AI产品经理必备技能:语音识别技术
-
从语音识别技术的发展可以看出:语音识别技术最早依靠匹配,寻找单个音节、单个词和标准语音模板的最大相似度进行匹配。后来伴随着统计学被引入到语音识别中,将该技术逐步从模板匹配技术转向基于统计模型技术。
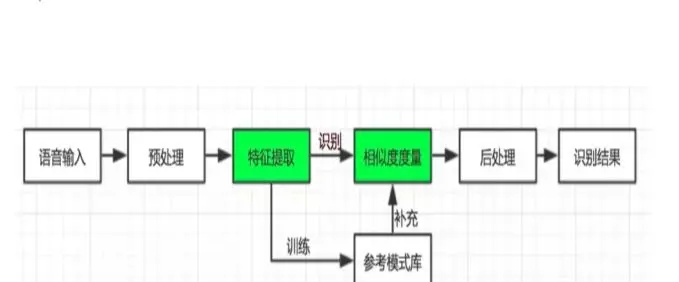
对于不同的语音识别过程,人们采用的识别方法和技术不同,但所用的原理大致相同,即将经过降噪处理后的语音送入特征提取模块,然后对语音信号特征处理后输出识别结果。在这个过程中,特征提取是构建语音系统的关键,对识别结果起到了重要作用。
实现语音识别,就需要语音参数来刻画语音信息。语音原本具有短时特性,所以描述语音的单位用帧(一般为10-40ms),在音频帧上提取的短时音频特征,叫音频帧特征。相对音频帧较长的时间间隔成为音频段,在音频段上提取的特征叫音频段特征。
原始语音信号传入预处理模块的目的:是为了压缩原始语音数据,提取出有代表性的特征来做后续的识别,主要分为三部分:预加重、分帧加窗、端点检测。

西南地区IT社群(QQ)
- 云南
- 【昆明网页设计交流吧】243627302
- 【昆明nodejs交流吧】 243626749
- 【VUE】838405306
- 【云南程序员总群】343606807
- 【昆明UI设计】104031254
- 【云南软件外包】15547313
- 贵州
- 【PHP/java源码/站长交流群】55692114
- 四川
- 【成都Java/JavaWeb交流】86669225
- 【vaScript+PHP+MySql】116270060
- 【UI设计/设计交流学习群】135794928
- 重庆
- 【诺基亚 JAVA游戏博物馆】 559479780
- 【PHP,Java,Python,C++接单】 442103442
- 西藏