基于机器学习的数据库调优AutoTiKV
-
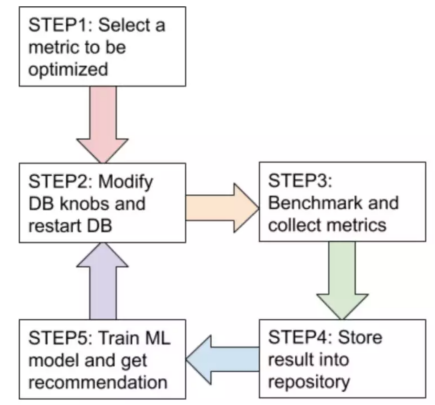
AutoTiKV 是一个用于对 TiKV 数据库进行自动调优的工具。
AutoTiKV 支持在修改参数之后重启 TiKV(如果不需要也可以选择不重启)。需要调节的参数和需要查看的 metric 可以在 controller.py 里声明。
一开始的 10 轮(具体大小可以调节)是用随机生成的 knob 去 benchmark,以便收集初始数据集。之后的都是用 ML 模型推荐的参数去 benchmark。
AutoTiKV 使用了和 OtterTune 一样的高斯过程回归(Gaussian Process Regression,以下简称 GP)来推荐新的 knob[1],它是基于高斯分布的一种非参数模型。
高斯过程回归的好处是:1. 和神经网络之类的方法相比,GP 属于无参数模型,算法计算量相对较低,而且在训练样本很少的情况下表现比 NN 更好。2. 它能估计样本的分布情况,即 X 的均值 m(X) 和标准差 s(X)。GP 本身其实只能估计样本的分布,为了得到最终的预测值,我们需要把它应用到贝叶斯优化(Bayesian Optimization)中。
贝叶斯优化算法大致可分为两步:1.通过 GP 估计出函数的分布情况。2.通过采集函数(Acquisition Function)指导下一步的采样(也就是给出推荐值)。采集函数(Acquisition Function)的作用是:在寻找新的推荐值的时候,平衡探索(exploration)和利用(exploitation)两个性质:exploration:在目前数据量较少的未知区域探索新的点。exploitation:对于数据量足够多的已知区域,利用这些数据训练模型进行估计,找出最优值。
在推荐的过程中,需要平衡上述两种指标。exploitation 过多会导致结果陷入局部最优值(重复推荐目前已知的最好的点,但可能还有更好的点没被发现),而 exploration 过多又会导致搜索效率太低(一直在探索新区域,而没有对当前比较好的区域进行深入尝试)。而平衡二者的核心思想是:当数据足够多时,利用现有的数据推荐;当缺少数据时,我们在点最少的区域进行探索,探索最未知的区域能给我们最大的信息量。
在具体实现中,一开始随机生成若干个 candidate knobs,然后用上述模型计算出它们的 U(X),找出 U(X) 最大的那一个作为本次推荐的结果。

西南地区IT社群(QQ)
- 云南
- 【昆明网页设计交流吧】243627302
- 【昆明nodejs交流吧】 243626749
- 【VUE】838405306
- 【云南程序员总群】343606807
- 【昆明UI设计】104031254
- 【云南软件外包】15547313
- 贵州
- 【PHP/java源码/站长交流群】55692114
- 四川
- 【成都Java/JavaWeb交流】86669225
- 【vaScript+PHP+MySql】116270060
- 【UI设计/设计交流学习群】135794928
- 重庆
- 【诺基亚 JAVA游戏博物馆】 559479780
- 【PHP,Java,Python,C++接单】 442103442
- 西藏