集成学习
-
集成学习从直观的意思来说,就是合众人之力来解决一个问题,而每个人所起的作用又不相同,最终把大家的力量进行“集成”,从而得到更优的方案。
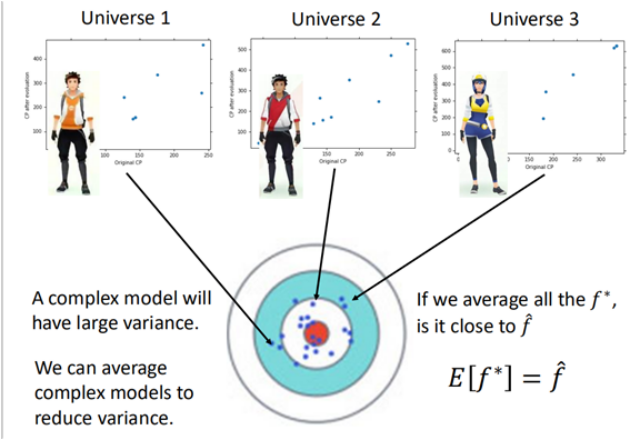
在前面线性回归的误差分析中说到,误差来源于偏差bias和方差variance,而简单的模型通常具有较大的偏差,从而出现欠拟合,复杂的模型具有较大的方差,出现过拟合的情况。
在线性回归中,当我们训练一系列的模型的时候(在平行宇宙中,训练出来n多个模型),当采用较为-
简单的模型的时候,最终形成的是偏差大方差小的结果:

-
而当模型采用比较复杂的时候,训练的结果是这样的:

而集成学习就根据消除偏差和方差,出现了两个系列的方法bagging和boosting。
Bagging
当使用复杂的模型训练出多个模型的时候,出现方差很大的情况,通过将模型进行“平均”,从而降低模型的方差。
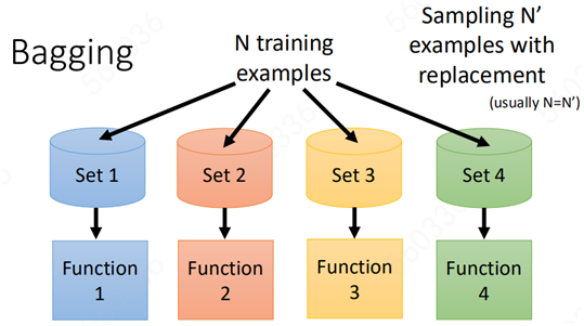
而Bagging就是为了解决方差过大的问题而提出的一种方法,即“集合”多个模型来共同决定结果。
那么Bagging中的多个模型又是从何而来呢?
这就是Bagging的主要思想:将一整个数据集拆分出多个数据集,然后根据数据集的不同来训练出来多个模型。
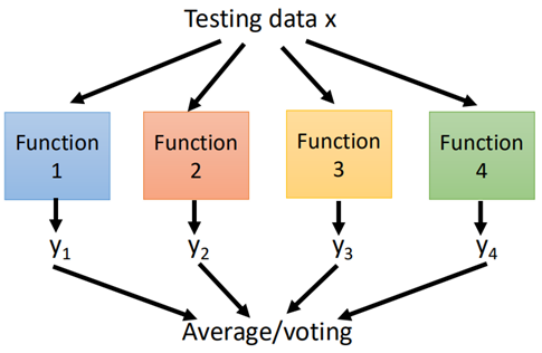
然后根据所训练得到的模型,测试集分别丢进每个模型中,然后通过投票的方式(不局限)得到最终的结果。
上面说到,Bagging能够很好地将多个复杂模型的方差进行平均后,从而得到一个方差较小的模型。也就是说Bagging能够有效的处理方差较大的问题。再换句话说就是Bagging方法中所选用的模型越复杂越好,也就是强分类器。
Bagging中一个最著名的算法就是随机森林(Random Forest),所谓随机森林就是选用了决策树作为基分类器的Bagging方法。
之所以选用决策树,是因为决策树具有很强的分类能力,甚至每一个样本都可以有一个叶子节点,很容易做到在训练集的误差为0。因此也很容易过拟合。
而随机森林另一个特点是不单单在训练每一颗树时所采用的样本是随机采样的,在每个节点进行分裂时的特征也是随机抽取的,从随机抽取的那一部分特征中再选出最优的特征进行分裂。
之所以这样做是因为如果单单对于训练集进行重采样的话,这样得到的树都相差不大,从而在最终决策时差别可能不会太大。
对于Bagging方法的测试,通常采用OOB(Out of Bag)的方法来进行测试,所谓OOB方法,假设一个数据集只有4笔数据,那么利用Bagging方法训练时:
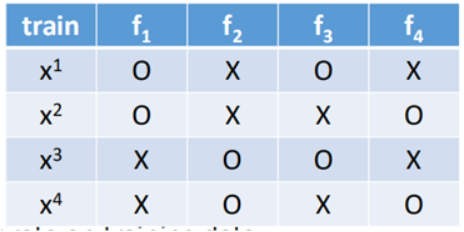
f1使用了x1、x2进行训练得到,f2使用了x3、x4训练得到,f3使用x1、x3训练得到,f4使用x2、x4训练得到,那么在测试时,使用f2+f4来测试x1,f2+f3来测试x2,f1+f4来测试x3,f1+f3来测试x4。
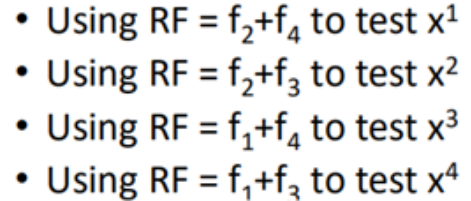
因为对于每一个模型的组合而言,这一个数据对这个组个是从来没有见过的,能够较好的估计出测试误差。 -

西南地区IT社群(QQ)
- 云南
- 【昆明网页设计交流吧】243627302
- 【昆明nodejs交流吧】 243626749
- 【VUE】838405306
- 【云南程序员总群】343606807
- 【昆明UI设计】104031254
- 【云南软件外包】15547313
- 贵州
- 【PHP/java源码/站长交流群】55692114
- 四川
- 【成都Java/JavaWeb交流】86669225
- 【vaScript+PHP+MySql】116270060
- 【UI设计/设计交流学习群】135794928
- 重庆
- 【诺基亚 JAVA游戏博物馆】 559479780
- 【PHP,Java,Python,C++接单】 442103442
- 西藏