Kafka的性能为什么这么快
-
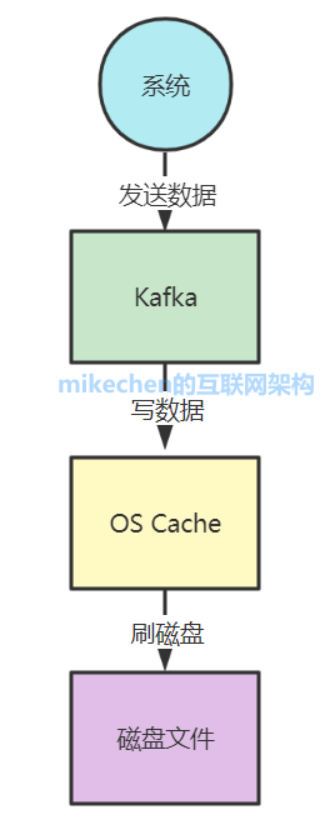
页缓存技术:Kafka 是基于操作系统 的页缓存(page cache)来实现文件写入的,我们也可以称之为 os cache,意思就是操作系统自己管理的缓存。
Kafka 在写入磁盘文件的时候,可以直接写入这个 os cache 里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把 os cache 里的数据真的刷入磁盘文件中。
通过这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘,原理图如下:
磁盘顺序写:另一个主要功能是 kafka 写数据的时候,是以磁盘顺序写的方式来写的,也就是说仅仅将数据追加到文件的末尾,不是在文件的随机位置来修改数据。
为什么要采用磁盘顺序写?
完成一次磁盘 IO,需要经过寻道、旋转和数据传输三个步骤:
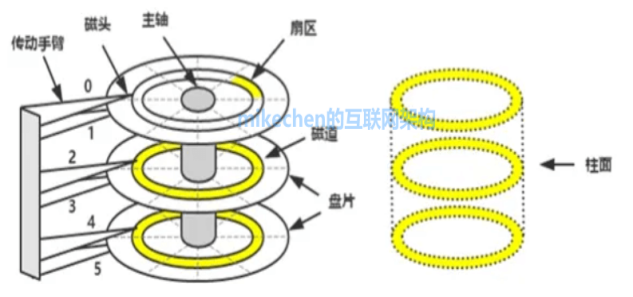
寻道(时间):磁头移动定位到指定磁道;旋转延迟(时间):等待指定扇区从磁头下旋转经过;数据传输(时间):数据在磁盘、内存与网络之间的实际传输。
零拷贝:先来看看非零拷贝的情况,如下图所示:可以看到数据的拷贝从内存拷贝到 Kafka 服务进程那块,又拷贝到 Socket 缓存那块,整个过程耗费的时间比较高。
Kafka 利用了 Linux 的 sendFile 技术(NIO),省去了进程切换和一次数据拷贝,让性能变得更好,如下图所示:
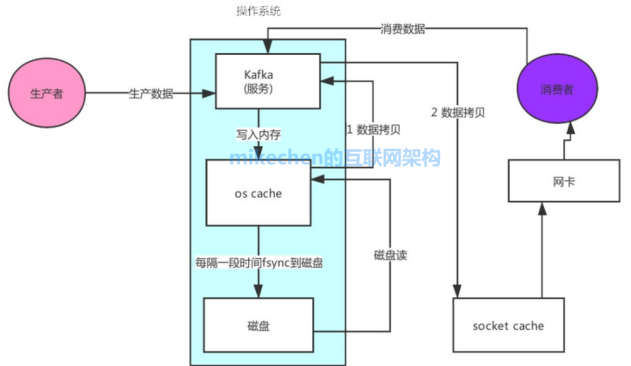
通过 零拷贝技术,就不需要把 os cache 里的数据拷贝到应用缓存,再从应用缓存拷贝到 Socket 缓存了,两次拷贝都省略了,所以叫做零拷贝。
分区分段+索引:Kafka 的 message 是按 topic分 类存储的,topic 中的数据又是按照一个一个的 partition 即分区存储到不同 broker 节点。每个 partition 对应了操作系统上的一个文件夹,partition 实际上又是按照segment分段存储的。
通过这种分区分段的设计,Kafka 的 message 消息实际上是分布式存储在一个一个小的 segment 中的,每次文件操作也是直接操作的 segment。为了进一步的查询优化,Kafka 又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度。

西南地区IT社群(QQ)
- 云南
- 【昆明网页设计交流吧】243627302
- 【昆明nodejs交流吧】 243626749
- 【VUE】838405306
- 【云南程序员总群】343606807
- 【昆明UI设计】104031254
- 【云南软件外包】15547313
- 贵州
- 【PHP/java源码/站长交流群】55692114
- 四川
- 【成都Java/JavaWeb交流】86669225
- 【vaScript+PHP+MySql】116270060
- 【UI设计/设计交流学习群】135794928
- 重庆
- 【诺基亚 JAVA游戏博物馆】 559479780
- 【PHP,Java,Python,C++接单】 442103442
- 西藏