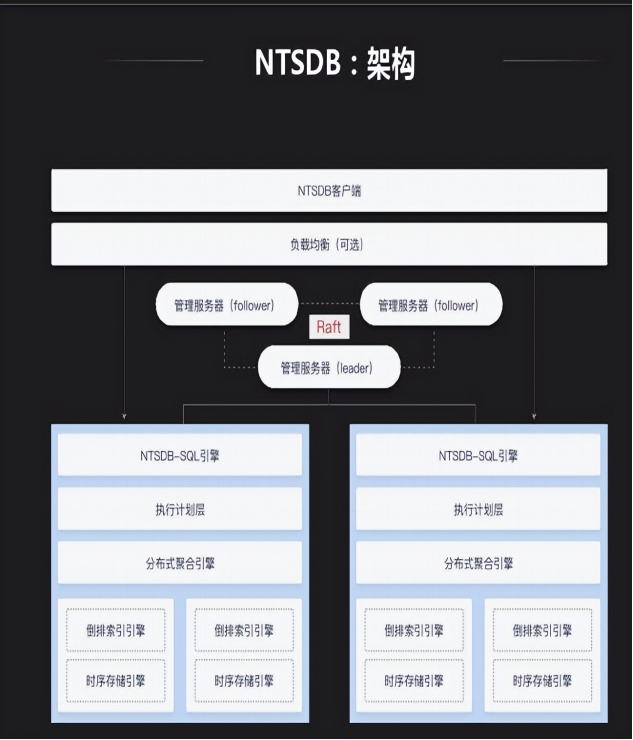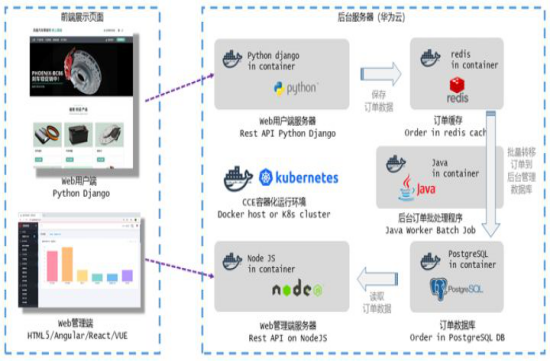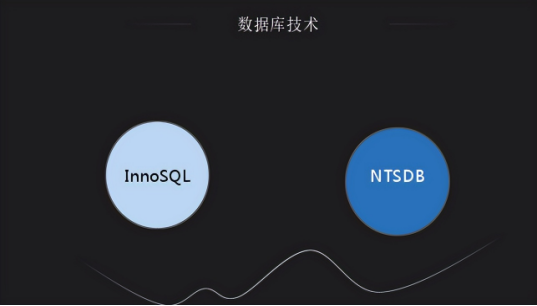
数据技术主要有InnoSQL和NTSDB,NTSDB是最近研发的新产品,预计明年将向外推荐此产品,InnoSQL属于MySQL分支方面的研究大概从2011年开始的,InnoSQL的主要目标是提供更好的性能以及高可用性,同时便于DBA的运维以及监控管理。

RocksDB是以树的形式组织数据的产品,MySQL有一个MyRocks产品,我们内部将其集成到InnoSQL分支上。这样做的原因是公司有很多业务,很多都是利用缓存保持其延迟,其规模会越来越大,这样就导致缓存、内存成本很高;其业务对延迟要求不是特别高,但要保持延迟稳定(小于50毫秒)。
RocksDB能够很好地将缓存控制的很好,随着缓存越来越大,有的公司会将其放到HBase上,但是其延迟有时波动会很大,如小米HBase很强,但还是做了一个基于K-V模式的缓存处理,主要解决延迟波动问题。我们主要是基于开源产品来解决,如将RocksDB集成起来解决公司业务对延迟稳定的一些需求。
InnoRocks由于是基于LSM,因此对写入支持非常好,后续有内部测试数据可以展示。还有就是LSM压缩比很高,网易一种是替换缓存,一种是普通数据库存储,目前还是用InnoDB存储,如果用InnoRocks存储会节省很多存储空间;还有一个就是结合DB做扩展,将其集成到公司内部。
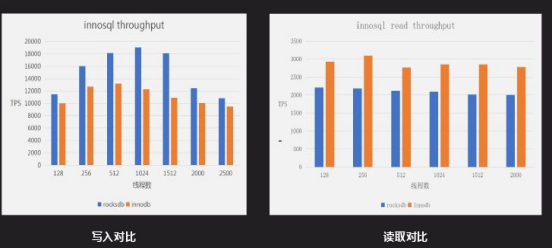
上图是写入对比,是一个普通的写入测试,其主介质是递增型的,对于两个都是一个顺序读写过程;如果要完全对比还要测试RFID写入测试,这样能够明显反应RocksDB和InnoDB的差距。图中RocksDB写入性能比InnoDB要好,读取性能InnoDB性能比RocksDB。300GB原始数据,分别导入到Inno DB(未压缩)和Inno Rocks后的存储容量对比,Inno DB为315GB左右,Inno Rocks为50 ~ 60GB,存储容量是Inno DB的20%到30%。
InnoRock一般场景是替换InnoDB写入,因为其写入性能、压缩性能更好、成本也更低。另一方面能够解决InnoDB延迟不稳定,替换大量的缓存应用,只要其对相应时间没有特殊要求。
大量数据写入场景,比如日志、订单等;需要高压缩以便存储更多的数据,Inno DB --> Inno Rocks;对写入延迟波动比较敏感,HBase --> Inno Rocks;相对较低的延迟要求(10 ~ 50ms)下替换缓存场景(延迟<5ms),节省内存成本, Redis --> Inno Rocks。