Burp Scanner是一个进行自动发现 web应用程序的安全漏洞的工具。它是为渗透测试人员设计的,并且它和你现有的手动执行进行的 web应用程序半自动渗透测试的技术方法很相似。
使用的大多数的 web扫描器都是单独运行的:你提供了一个开始 URL,单击”go”,然后注视着进度条的更新直到扫描结束,最后产生一个报告。Burp Scanner和这完全不同,在攻击一个应用程序时它和你执行的操作紧紧的结合在一起。让你细微控制着每一个扫描的请求,并直接反馈回结果。
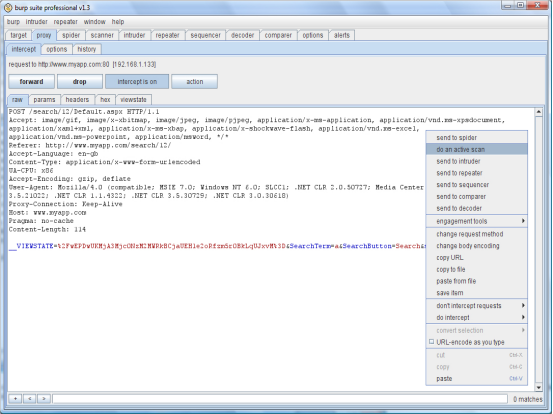
Burp Scanner可以执行两种扫描类型:Active scanning扫描器向应用程序发送大量的伪造请求,这些请求都是有一个基础请求衍生出来的,然后通过分析响应结果来查找漏洞特征。
Passive scanning扫描器不发送他自己的任何新请求,只分析现有的请求和响应的内容,从这些信息中推断出漏洞。
你可以在目标应用程序使用两种不同方式:Manual scanning你可以发送其他 Burp工具的一个或多个请求,来对这些特定的请求执行主动或被动的扫描。Live scanning as you browse你可以配置扫描器来自动执行主动或被动的扫描那些你浏览应用程序时经过代理的请求。
这种自动探测漏洞的方法给渗透测试人员带来了几点好处:通过逐个的请求,能快速可靠地对常规的漏洞进行扫描,这很大程度地减少你的测试精力,还能使你对那些不能进行自动可靠地探测的漏洞直接使用个人经验来判断。每种扫描的结果会被立即显示出来,并通报出在这个请求中包含的其他的测试操作。Burp避免了其他扫描器的令人沮丧的问题,进行一次自动扫描需要 1年的时间,并还不能保证扫描是否有效,或者是否遇到了影响扫描效率的问题。
Burp精准地控制着要扫描的内容,并对扫描结果和应用程序上的广范围的影响进行实时监控,Burp Spider让你把可靠自动化的优点和人类直观智慧结合起来,常常会得到压倒性的结果。