MiniWord .NET Word模板引擎,藉由Word模板和数据简单、快速生成文件。
-
特点:简单:只用简单标记,无需学习语法,JSON数据,简单通用!
-
易用:直接用Office设计,无需学习复杂设计工具,模板就是需求文档!
-
强大:图片、列表、表格、图表、HTML全能,同时支持docx/xlsx/pptx!
-
智能:自动识别文档格式,自动生成示例数据,自动生成调用代码!
MiniWord .NET Word模板引擎,藉由Word模板和数据简单、快速生成文件。
特点:简单:只用简单标记,无需学习语法,JSON数据,简单通用!
易用:直接用Office设计,无需学习复杂设计工具,模板就是需求文档!
强大:图片、列表、表格、图表、HTML全能,同时支持docx/xlsx/pptx!
智能:自动识别文档格式,自动生成示例数据,自动生成调用代码!
当要处理数字信号,直接利用将各个处理阶段(过滤、校正、分析、检测... )设计成的处理块,可以使用简单的流程指示箭头进行连接:
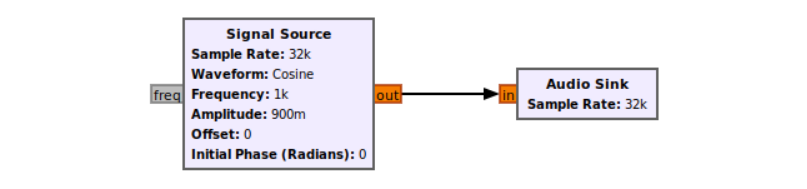
当要建立信号处理应用程序时,需要建立完整的块图。这样的图在 GNU Radio 中称为流程图。
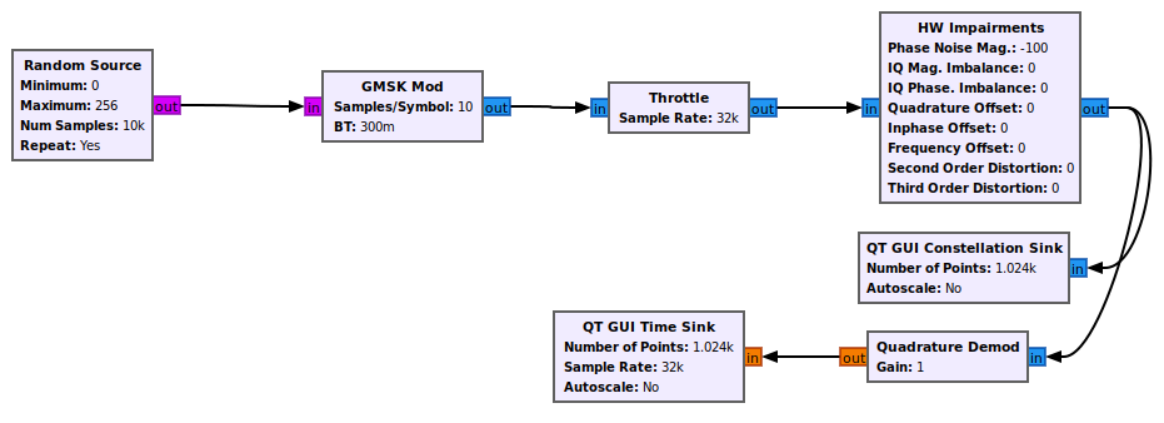
GNU Radio 是一个开发这些处理块并创建包含无线电处理应用程序的流程图的框架。
作为 GNU Radio 用户,您可以将现有块组合到一个高级流程图中,GNU Radio 将自动在这些块之间移动信号数据并在块中进行信号处理。
GNU Radio 提供大量的块,使用这些块能快速设计流程图来完成许多标准任务 —— 标准化、同步、测量和可视化。
GNU Radio 也支持用户自己设计块:因此,GNU Radio 主要是信号处理块及其交互作用开发的框架,它带有广泛的标准块库,开发人员可以构建许多可用系统。但是 GNU Radio 本身并不是准备做特定事情的软件 —— 尽管它已经附带了许多有用的工作示例。但是用户的工作就是从中构建有用的东西,可以将示例视为一组构建块。
即时编译器的目的是避免函数被解释执行,而是将整个函数体编译成机器码指令,每次函数执行时,只执行编译后的机器码即可,这种方式可以大大的提高效率。
热点代码及探测方式:当然,是否需要JIT编译器将字节码直接编译成对应平台的机器码,需要根据代码被调用的执行频率而定。需要被JIT编译器编译成机器码的字节码,也称为热点代码,JIT编译器会对热点代码做出深度优化,将其从字节码编译成机器码,并缓存到方法区,提高代码的执行效率。
JIT编译的方式发生在方法执行过程中,因此也被称之为_栈上替换_,或简称OSR(On Stack Replacement)编译。通过热点探测的方法,判断一个方法被调用多少次,或循环体执行多少次才可以达到阈值,进行编译。而Hotspot VM热点探测的方式是基于计数器实现的。这种基于技术的热点探测方式又分为两种:1.方法调用计数器 2.回边计数器。
方法调用计数器:方法调用计数器用于统计方法调用次数,它的默认阈值是client模式下是1500次,在server模式下是10000次。超过这个阈值,就会触发JIT编译。当然,这个阈值也可以通过修改虚拟机参数-XX:CompileThreshold来手动指定。
当一个方法被调用的时候,会优先检查该方法是否被JIT编译过,如果存在,则优先使用编译过的本地代码来执行,如果不存在,则将此方法的调用计数器加一,然后再判断计数器的值是否超过配置的阈值。如果已经超过了,就会向JIT编译器提交一个该方法的编译请求。下面是方法调用计数器执行的流程图:
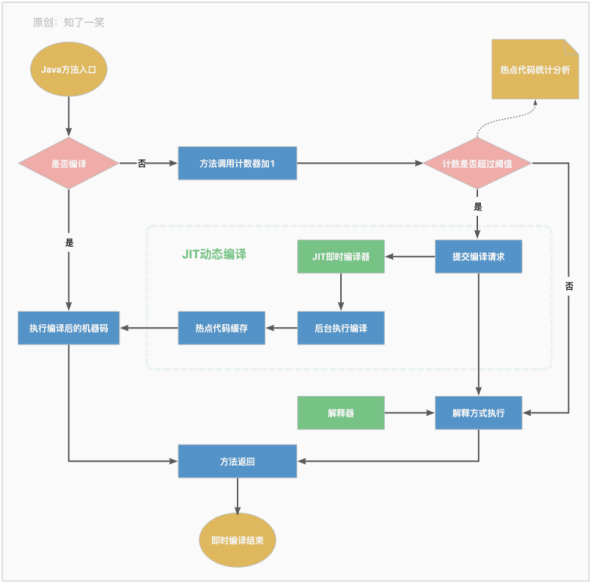
关于方法调用计数器,如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对执行的频率。当超过一定的时间限度,如果方法的调用次数仍然达不到阈值,那这个方法的调用计数器就会被减少一半,这个过程称为方法调用计数器的热度衰减,而这段时间被称作为该方法的半衰周期。
进行热度衰减的过程是虚拟机进行垃圾回收的时候顺便进行的,举手之劳而已。可以使用虚拟机参数-XX:-UseCounterDecay来关闭热度衰减。这样的话,只要运行时间足够长,绝大部分方法都会被编译成本地代码。最后,还可以使用-XX:CounterHalfLifeTime参数设置半衰周期的时间,单位为秒。
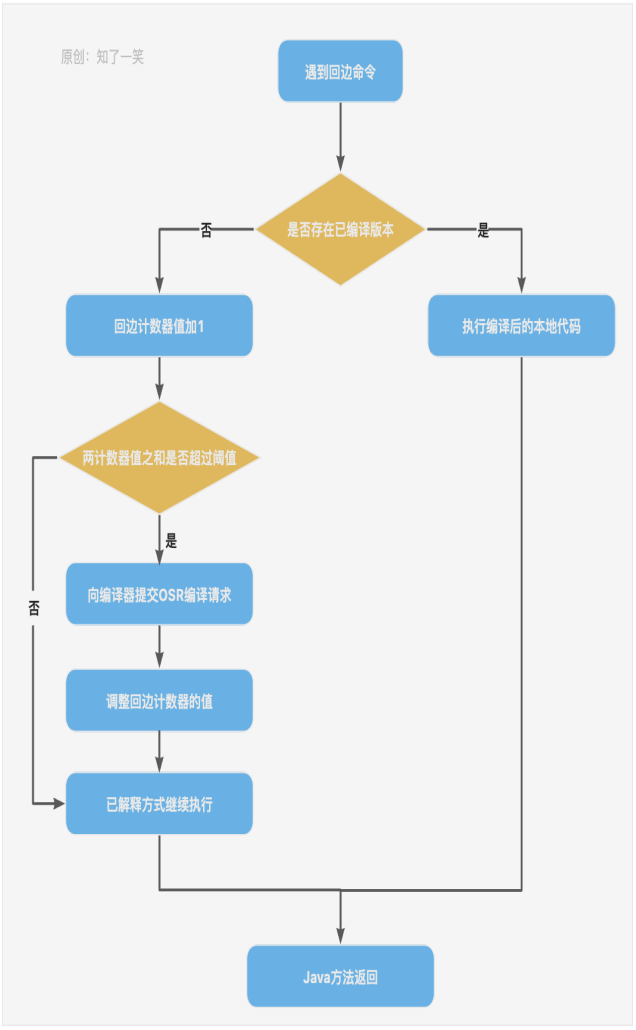
回边计数器:它的作用是统计一个方法中循环体代码执行次数,在字节码中遇到控制流向后,跳转的指令称为“回边”。显然,建立回边计数器统计的目的是为了触发OSR编译。下面是回边计数器执行的流程图:
关于OSR编译上文中有提到
即时编译器分类:在Hotspot VM中,内嵌有两个JIT编译器,分别为client compiler和server compiler,但是大多数情况下我们简称C1编译器和C2编译器。可以通过命令显示的指定JVM在运行时到底使用哪种JIT编译器。
集成学习从直观的意思来说,就是合众人之力来解决一个问题,而每个人所起的作用又不相同,最终把大家的力量进行“集成”,从而得到更优的方案。
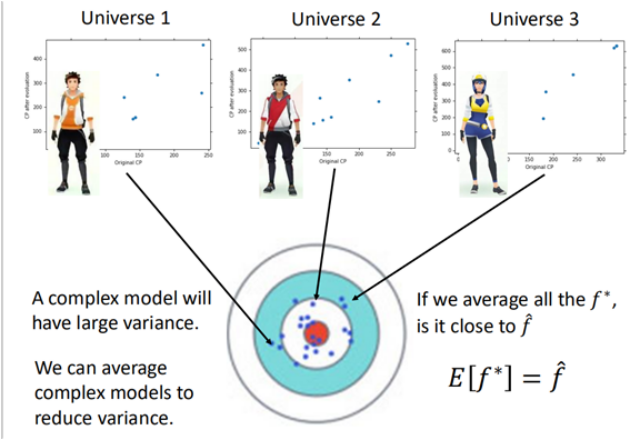
在前面线性回归的误差分析中说到,误差来源于偏差bias和方差variance,而简单的模型通常具有较大的偏差,从而出现欠拟合,复杂的模型具有较大的方差,出现过拟合的情况。
在线性回归中,当我们训练一系列的模型的时候(在平行宇宙中,训练出来n多个模型),当采用较为
简单的模型的时候,最终形成的是偏差大方差小的结果:

而当模型采用比较复杂的时候,训练的结果是这样的:

而集成学习就根据消除偏差和方差,出现了两个系列的方法bagging和boosting。
Bagging
当使用复杂的模型训练出多个模型的时候,出现方差很大的情况,通过将模型进行“平均”,从而降低模型的方差。
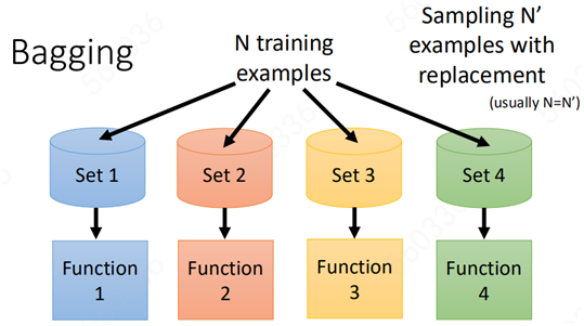
而Bagging就是为了解决方差过大的问题而提出的一种方法,即“集合”多个模型来共同决定结果。
那么Bagging中的多个模型又是从何而来呢?
这就是Bagging的主要思想:将一整个数据集拆分出多个数据集,然后根据数据集的不同来训练出来多个模型。
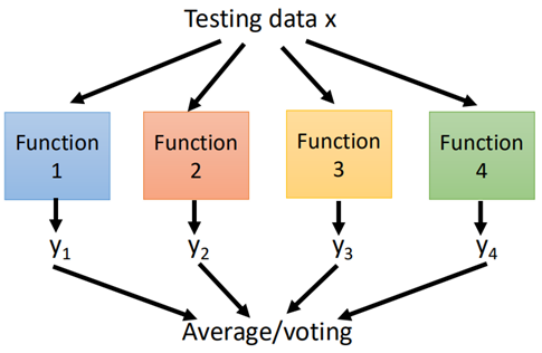
然后根据所训练得到的模型,测试集分别丢进每个模型中,然后通过投票的方式(不局限)得到最终的结果。
上面说到,Bagging能够很好地将多个复杂模型的方差进行平均后,从而得到一个方差较小的模型。也就是说Bagging能够有效的处理方差较大的问题。再换句话说就是Bagging方法中所选用的模型越复杂越好,也就是强分类器。
Bagging中一个最著名的算法就是随机森林(Random Forest),所谓随机森林就是选用了决策树作为基分类器的Bagging方法。
之所以选用决策树,是因为决策树具有很强的分类能力,甚至每一个样本都可以有一个叶子节点,很容易做到在训练集的误差为0。因此也很容易过拟合。
而随机森林另一个特点是不单单在训练每一颗树时所采用的样本是随机采样的,在每个节点进行分裂时的特征也是随机抽取的,从随机抽取的那一部分特征中再选出最优的特征进行分裂。
之所以这样做是因为如果单单对于训练集进行重采样的话,这样得到的树都相差不大,从而在最终决策时差别可能不会太大。
对于Bagging方法的测试,通常采用OOB(Out of Bag)的方法来进行测试,所谓OOB方法,假设一个数据集只有4笔数据,那么利用Bagging方法训练时:
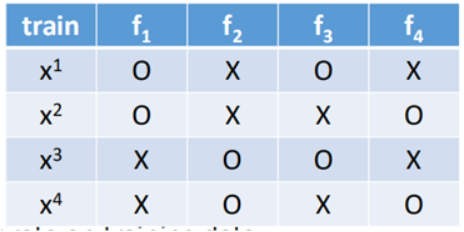
f1使用了x1、x2进行训练得到,f2使用了x3、x4训练得到,f3使用x1、x3训练得到,f4使用x2、x4训练得到,那么在测试时,使用f2+f4来测试x1,f2+f3来测试x2,f1+f4来测试x3,f1+f3来测试x4。
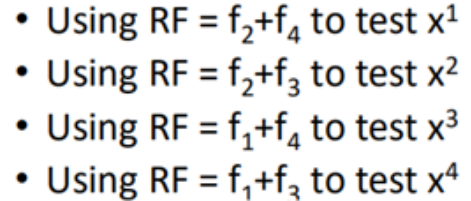
因为对于每一个模型的组合而言,这一个数据对这个组个是从来没有见过的,能够较好的估计出测试误差。
每一个被调用服务都会有多个实例,那么服务的调用方应该将请求,发向被调用服务的哪一个服务实例,这就是负载均衡的业务场景。
负载均衡的第一个关键点是公平性,即负载均衡需要关注被调用服务实例组之间的公平性,不要出现旱的旱死,涝的涝死的情况。
负载均衡的第二个关键点是正确性,即对于有状态的服务来说,负载均衡需要关心请求的状态,将请求调度到能处理它的后端实例上,不要出现不能处理和错误处理的情况。
无状态的负载均衡是我们日常工作中接触比较多的负载均衡模型,它指的是参与负载均衡的后端实例是无状态的,所有的后端实例都是对等的,一个请求不论发向哪一个实例,都会得到相同的并且正确的处理结果,所以无状态的负载均衡策略不需要关心请求的状态。下面介绍两种无状态负载均衡算法。
轮询的负载均衡策略非常简单,只需要将请求按顺序分配给多个实例,不用再做其他的处理。例如,轮询策略会将第一个请求分配给第一个实例,然后将下一个请求分配给第二个实例,这样依次分配下去,分配完一轮之后,再回到开头分配给第一个实例,再依次分配。轮询在路由时,不利用请求的状态信息,属于无状态的负载均衡策略,所以它不能用于有状态实例的负载均衡器,否则正确性会出现问题。在公平性方面,因为轮询策略只是按顺序分配请求,所以适用于请求的工作负载和实例的处理能力差异都较小的情况。
权重轮询的负载均衡策略是将每一个后端实例分配一个权重,分配请求的数量和实例的权重成正比轮询。例如有两个实例 A,B,假设我们设置 A 的权重为 20,B 的权重为 80,那么负载均衡会将 20% 的请求数量分配给 A,80 % 的请求数量分配给 B。权重轮询在路由时,不利用请求的状态信息,属于无状态的负载均衡策略,所以它也不能用于有状态实例的负载均衡器,否则正确性会出现问题。在公平性方面,因为权重策略会按实例的权重比例来分配请求数,所以,我们可以利用它解决实例的处理能力差异的问题,认为它的公平性比轮询策略要好。
有状态负载均衡是指,在负载均衡策略中会保存服务端的一些状态,然后根据这些状态按照一定的算法选择出对应的实例。
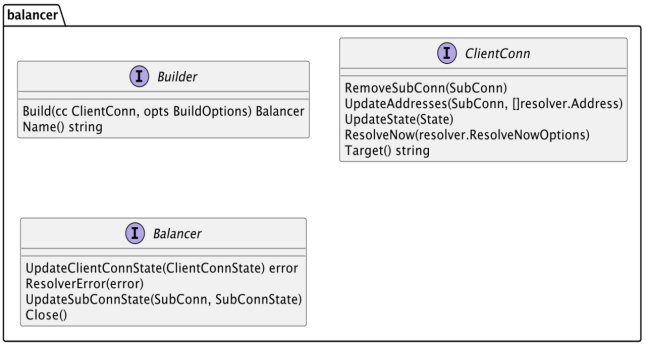
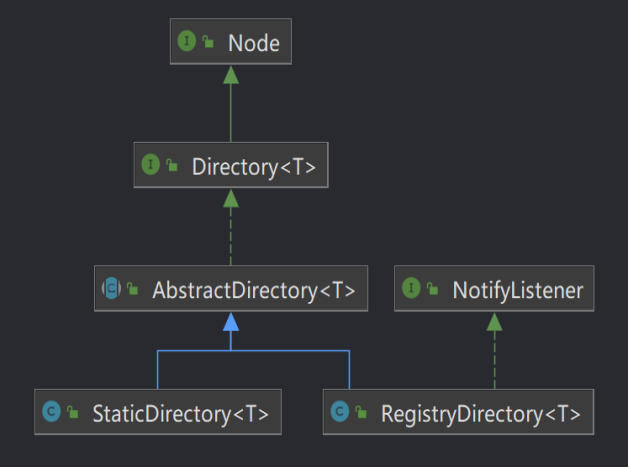
服务目录目前内置的实现有两个,分别为 StaticDirectory 和 RegistryDirectory。它们均继承自AbstractDirectory,而 AbstractDirectory 实现了 Directory 接口。Directory 接口提供了list(Invocation invocation) 方法,这个方法就是用来获取 invoker 集合的。
再看 RegistryDirectory 实现了 NotifyListener 接口,这个接口中只有一个方法,notify(List urls),当注册中心节点信息发生变化后,触发此方法调整服务目录中的配置信息以及 invoker 集合。
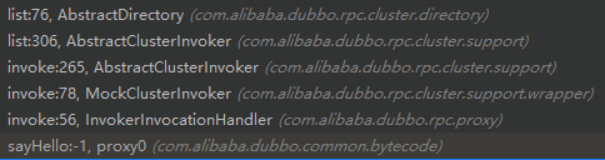
上面我们讲了,服务调用需求用到 invoker,而服务目录持有 invoker 集合,并通过 list 方法提供 invoker。下面放上服务消费者Demo中DemoService#sayHello 方法的调用路径
Ring 3层的 IAT HOOK 和 EAT HOOK 其原理是通过替换IAT表中函数的原始地址从而实现Hook的,与普通的 InlineHook 不太一样 IAT Hook 需要充分理解PE文件的结构才能完成 Hook,接下来将具体分析 IAT Hook 的实现原理,并编写一个DLL注入文件,实现 IAT Hook 。
在早些年系统中运行的都是DOS应用,所以DOS头结构就是在那个年代产生的,那时候还没有PE结构的概念,不过软件行业发展到今天DOS头部分的功能已经无意义了,但为了最大的兼容性微软还是保留了DOS文件头,有些软件在识别程序是不是可执行文件的时候通常会读取PE文件的前两个字节来判断是不是MZ。
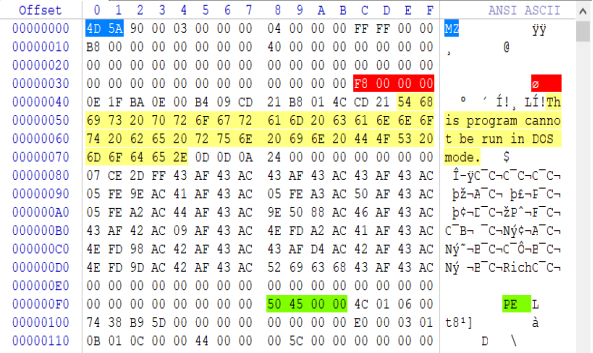
上图就是PE文件中的DOS部分,典型的DOS开头ASCII字符串MZ幻数,MZ是Mark Zbikowski的缩写,Mark Zbikowski是MS-DOS的主要开发者之一,很显然这个人给微软做出了巨大的贡献。
在DOS格式部分我们只需要关注标红部分,标红部分是一个偏移值000000F8h该偏移值指向了PE文件中的标绿部分00004550指向PE字符串的位置,此外标黄部分为DOS提示信息,当我们在DOS模式下执行一个可执行文件时会弹出This program cannot be run in DOS mode.提示信息。
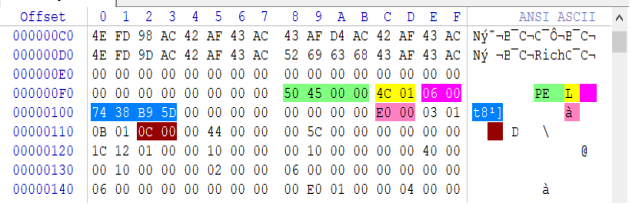
上图中在PE字符串开头位置向后偏移1字节,就能看到黄色的014C此处代表的是机器类别的十六进制表示形式,在向后偏移1个字节是紫色的0006代表的是程序中的区段数,继续向后偏移1字节会看到蓝色的5DB93874此处是一个时间戳,代表的是自1970年1月1日至当前时间的总秒数,继续向后可看到灰色的000C此处代表的是链接器的具体版本。
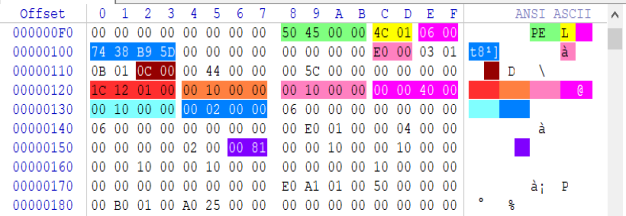
上图中我们以PE字符串为单位向后偏移36字节,即可看到文件偏移为120处的内容,此处的内容是我们要重点研究的对象。
在文件FOA偏移为120的位置,可以看到标红色的地址0001121C此处代表的是程序装入内存后的入口点(虚拟地址),而紧随其后的橙色部分00001000就是代码段的基址,其后的粉色部分是数据段基址,在数据基址向后偏移1字节可看到紫色的00400000此处就是程序的建议装入地址,如果编译器没有开启基址随机化的话,此处默认就是00400000,开启随机化后建议装入地址与实际地址将不符合。
继续向下文件FOA偏移为130的位置,第一处浅蓝色部分00001000为区段之间的对齐值,深蓝色部分00002000为文件对其值。
切勿在 GitHub 上存储凭据和敏感数据;GitHub 的目的是托管代码存储库。除了在帐户上设置的权限之外,没有其他安全方法可以确保您的密钥、私钥和敏感数据保留在受控且受保护的环境中。
Git code commit 保存了已添加和删除内容的历史记录,从而使敏感数据永久保留在分支上。当分支合并和 Fork 时,潜在的数据或基础架构安全风险可能会呈指数级增长。降低此风险的最简单方法是,在提交到分支之前不要在代码中存储凭据和敏感数据。可以在 CI/CD 流水线中使用 git-secreits 等工具。另一个方法是使用机密和身份管理工具,如 Vault 和 Keycloak。
禁用 Fork;分叉(fork)是一种 git 技术,它允许开发人员在不涉及原始代码的情况下创建代码仓库的副本。虽然 fork 非常适合实验和沙箱,但它也可能导致无法跟踪敏感数据和私有凭据的最终位置。代码仓库最初可能是私有的,但 fork 可以快速将所有内容暴露到公共空间中。风险随着每次分叉的发生呈指数级增加,通过暴露的敏感数据创建树状的安全漏洞链。为了防止这种情况发生,请禁用 Fork 存储库以帮助降低敏感数据进入代码的风险。
禁用可见性更改;有时开发人员拥有的权限和权限比其角色范围所需的权限更多。对于没有安全概念的开发人员来说,很容易不小心更改代码库的可见性。如果代码存储库中存在敏感数据,有权访问此更改可见性功能的人员越多,则潜在的风险就越高。要防止此类情况,可以将更改存储库可见性的功能设置为仅对组织所有者开放,或允许管理员特权成员使用权限。
验证 GitHub 应用程序;现在的开发团队有时由外部和第三方团队组成,因此验证 GitHub 应用程序涉及跟踪第三方开发人员及其可访问性级别。这也意味着,一旦他们离开项目,或者不再处理代码,就需要撤销他们的访问权限。不同程度的可访问性也应与他们在项目中的作用和参与程度挂钩。比如,代码审核只需要提取代码的能力,而不需要创建提交。只有在具有相应权限的人进行一系列检查和代码验证之后,才应进行拉取和合并请求。
执行双重认证;双重身份验证(2FA)现在是帐户安全的行业标准。它也应当成为组织的标准安全要求,来防止通过不安全的帐户泄漏代码。2FA 在登录 GitHub 时增加了一层额外的安全保护,并且可以通过组织的设置在组织级别强制执行。当保存设置后,系统可能会提示有关未激活 2FA 的个人详细信息。这些信息将从组织中删除,并且只有在其帐户上实施 2FA 后才能重新添加。可以在组织的审核日志中查看已删除的成员。
实行单节点登陆(仅限 GitHub Enterprise);SAML 单点登录 (Single Sign-On, SSO)是一项仅适用于 GitHub Enterprise 的功能。借助此功能,GitHub 上的组织可以通过显示授予对特定资源(如单个代码仓库、拉取请求和引发的问题)的访问权限来控制可访问性。这允许组织对代码推送、拉取和审阅过程的不同部分的可访问性进行分段。SAML SSO 还允许企业设置已批准的身份提供商。这意味着,企业可以限制用户仅使用组织的帐户登录,而不是使用个人 GitHub 帐户。这能够有效缓解在向 GitHub 帐户授予可访问性时可能发生的潜在安全风险。
限制访问允许的 IP 地址;对于大型企业而言,跟踪访问用户既困难又耗时。防止不必要的访问的方法是限制通过IP地址的访问。这意味着只有内部部署的成员或有权访问公司维护的静态 IP 远程网络的成员才能进入企业的代码存储库和相关代码工作。要限制、管理和将 IP 地址列入白名单,在这里可以以 CIDR 表示法配置特定 IP 地址或范围的列表。
严格管理外部参与者权限;企业可能通过外包来加快项目的进展,或者引入外部专业知识来帮助填补团队空白。外部成员的参与越多,相应的安全风险就越高。通过严格管理外部协作者和参与者,企业可以减少冗余用户数量及其对代码存储库的可访问性。管理外部协作者的一种方法是将访问权限和权限授予权限集中给管理员。这样做还可以降低由于 GitHub 的长期访问成本。
及时撤销权限;一个好的安全策略,需要考虑到团队成员离开企业或项目时,对应的权限进行怎样的修改和调整。这包括撤销不同类型帐户的可访问性的时间。有时团队成员可能仍需要访问代码,但不需要参与,因此撤销更改权限或将其切换为维护者角色可能更适合。此方法遵循最小特权原则,即授予执行特定任务所需的权限。这样做将确保每个有权访问代码的人都只在其权限范围内工作。
要求提交签名;提交签名是对代码合并进行加密签名以进行验证和可跟踪性的过程。这对于代码审核跟踪非常重要,因为恶意攻击者伪装成其他人并不难,只需在 git 配置中更改其用户名和电子邮件地址并推送剥削性代码合并。可以将 Git 设置为通过 GPG(GNU Privacy Guard)对提交进行签名,并在 git 配置中使用私有密钥配置提交。完成此操作后,您可以将 GPG key 添加到 GitHub。在提交时,提交旁边会显示一个“已验证”标志。
执行提交前代码审查;强制执行代码审查可以防止恶意代码正式合并到分支中。代码审查也是检测代码异常的良好做法,能够帮助企业避免导致未来的漏洞和长期的安全风险问题。GitHub 有一个拉取请求工具,允许授权的团队成员在合并到基本分支之前讨论和查看潜在的更改。发出拉取请求时,可以将工作负责人附加到拉取请求,来通知他们查看待处理的审核。

在.Net Framework环境下,我们使用Windows Workflow Foundation(WF)作为项目的工作流引擎,可是.Net Core已经不支持WF了,需要为基于.Net Core的项目选择新的工作流引擎。基本要求如下:
轻量级,部署和使用都很简单。有相当数量的用户,往往使用的人越多,产品也就越可靠,遇到问题也容易找到解决办法。支持使用配置文件定义工作流,而不仅仅是使用代码定义。
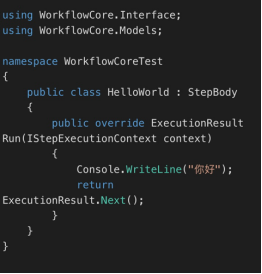
简单的控制台项目。首先,使用Visual Studio创建一个.Net Core的控制台项目,在NuGet管理器中引入下面程序包:WorkflowCore;Microsoft.Extensions.DependencyInjection;Microsoft.Extensions.Logging。

WorkflowHost的工作过程是这样的,首先需要获取WorkflowHost的实例,然后注册工作流,这里可以注册多个工作流,接下来,启动host,然后可以启动工作流,这里可以启动多个工作流实例,最后,关闭host。
我们需要对WorkflowHost有进一步的了解,第一个问题,每次使用serviceProvider.GetService()获得的host是否是同一对象?为了回答这个问题,我们增加一些代码:
![58c88f76-c51a-45a7-a78c-7d18e5500c6b-image.png]
微处理器具有以下基本功能:
指令控制:使计算机中的指令或程序严格按照规定的顺序执行。操作控制:将计算机指令产生的控制信号送往相应的部件,控制这些部件按指令的要求完成规定的工作。
时间控制:使计算机中各类控制信号严格按照时间上规定的先后顺序进行操作。
数据加工:对数据进行算术运算和逻辑运算等操作,或其他信息的处理。
8086微处理器的特点:采用了并行流水线工作方式,通过设置指令预取队列实现;对内存空间实行分段管理,实现对1MB空间的寻址;支持多处理器系统;工作于最小模式和最大模式两种工作模式。
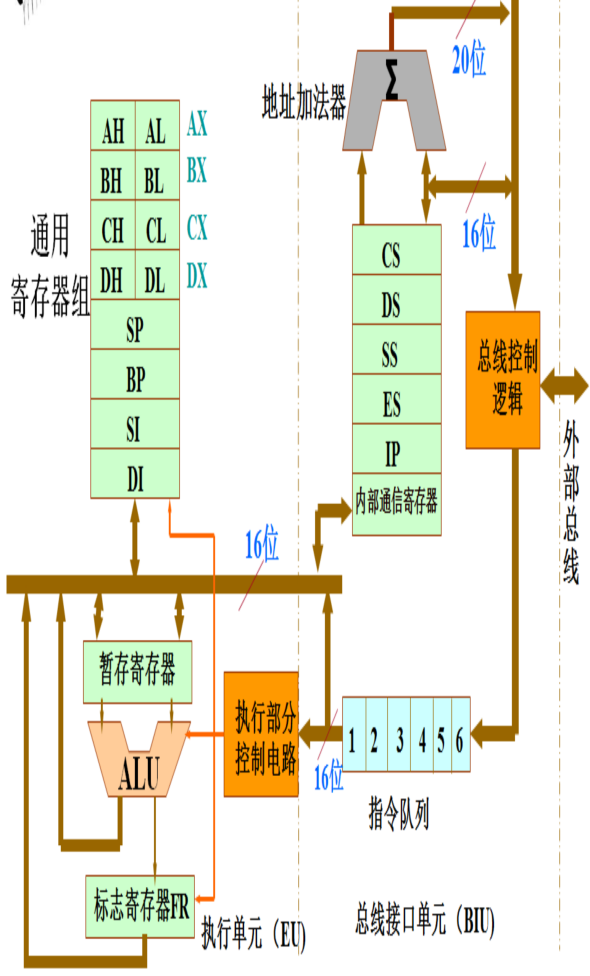
指令执行部件EU:算术逻辑运算单元ALU:完成8位或16位的二进制算术运算和逻辑运算;
运算结果送到通用寄存器或标志寄存器或写入存储器。
FR标志寄存器:用来存放ALU运算后的结果特征或机器运行状态。
数据暂存寄存器:暂时存放参加运算的操作数,不可编程。
通用寄存器组:4个16位数据寄存器: AX、BX、CX、DX;4个16位地址指针与变址寄存器: SP、BP、SI、DI。
EU控制电路:接收从BIU指令队列中取来的指令,经过指令译码形成各种定时控制信号,对EU的各个部件实现特定的定时操作。
总线接口单元BIU:根据EU的请求,完成CPU与存储器、I/O接口之间的信息传送。
提供从存储器取指令送指令队列或直接送EU执行;从存储器或外设取数据送EU,或把EU操作结果送存储器或外设。
4个16位段地址寄存器CS:代码段寄存器;
DS:数据段寄存器;
SS:堆栈段寄存器;
ES:扩展(附加)数据段寄存器。
16位指令指针寄存器IP:存放下一条将要执行指令的偏移地址(有效地址EA);
20位地址加法器:将16位的逻辑地址变换成访存储器的20位物理地址,完成地址加法操作。
6字节指令队列:预存6个字节的指令代码。
总线控制电路:发出总线控制信号。 将8086CPU内部总线与外部总线相连。
