信使是一个简洁的 IM。核心目标:完成单机 10W + 的可用项目 (目前实现网页端和 electron 实现的 Win 端)。核心 Tio, 包括 http 和 socket 都是 tio. 没有引入 spring 系列,所以大部分的内容都需要自己封装,好处是启动快,体积小。弊端就是方方面面都需要自己考虑。从登录开始所有的交互全部使用 socket,除 minio 分片上传使用了 http 外,目前没有其他使用 http 的地方。 文件存储使用了 minio, 缓存使用 mangodb, 同时解决缓存和数据存储的问题(据说挺快的,没有做大量尝试)
爱
爱的天地 发布的帖子
-
简洁的 IM courier-信使发布在 技术答疑
-
基于React的中后台应用解决方案飞冰ICE发布在 技术答疑
飞冰 (ICE) 是一套基于 React 的中后台应用解决方案,ICE 包含了一条从设计端到开发端的完整链路,帮助用户快速搭建属于自己的中后台应用。
面向设计者端,ICE 提供了 ICE Design 设计语言,来给 UI 界面提供专业的视觉指导。面向开发者端,ICE 提供了 Iceworks 工具,这是一个图形化界面的开发平台,它承载了 ICE 的物料体系和开发体验。在飞冰中,组件、区块、布局、模板等统称为物料,由飞冰团队维护,在内部有一套完整的开发规范和工具,目前也正在逐步对外开放中;基于此,你可以参与共建 ICE,也可以自建私有的物料体系。
-
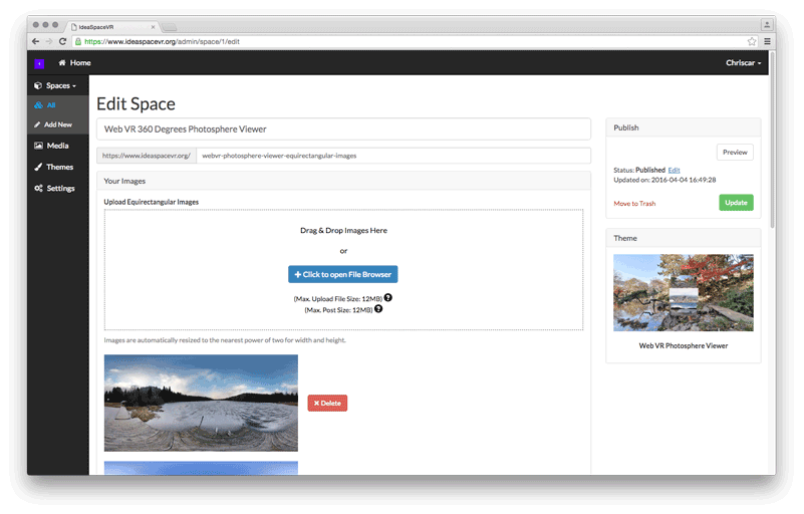
用于WebVR的内容管理系统IdeaSpace发布在 开源推荐
IdeaSpace 是一个用于虚拟现实网页的 CMS 内容管理系统。可以像管理博客一样管理你的虚拟现实空间和资源。IdeaSpace 使用 Mozilla 的 A-Frame 来实现主题和空间,提供强大的遵循 Web 标准的标识语言。可通过 Oculus Rift 或者 Google Cardboard 在浏览器上方便体验虚拟现实空间,无需安装插件和应用。
项目地址:
https://www.oschina.net/p/ideaspace
-
千亿参数预训练语言模型YaLM 100B发布在 开源推荐
YaLM 100B 是一个类似 GPT 的神经网络,用于生成和处理文本。该模型利用了 1000 亿个参数,在 800 个 A100 显卡和 1.7 TB 在线文本、书籍以及海量其他英文和俄文资源的集群上训练该模型花了 65 天时间。在下载权重之前,请确保有 200GB 的可用磁盘空间。该模型(代码基于 microsoft/DeepSpeedExamples/Megatron-LM-v1.1.5-ZeRO3)应该在具有张量并行性的多个 GPU 上运行。它在 4 个 (A100 80g) 和 8 个 (V100 32g) GPU 上进行了测试,能使用总计约 200GB 的 GPU 内存来正确划分权重维度(例如 16、64、128)的不同配置。
-
多功能透明显示屏桌面站HoloCubic发布在 技术答疑
HoloCubic 是一个带网络功能的伪全息透明显示桌面站。项目的硬件方案基于 ESP32PICO-D4,这是一个很实用的 SiP 芯片,整板面积能做到一个硬币大小;软件方面主要是基于 lvgl-GUI 库,移植了 ST7789 1.3 寸 240x240 分辨率屏幕的显示驱动,同时将 MPU6050 作为输入设备,通过感应的方式模拟编码器键值。
-
Spring Cloud项目发布在 开源推荐
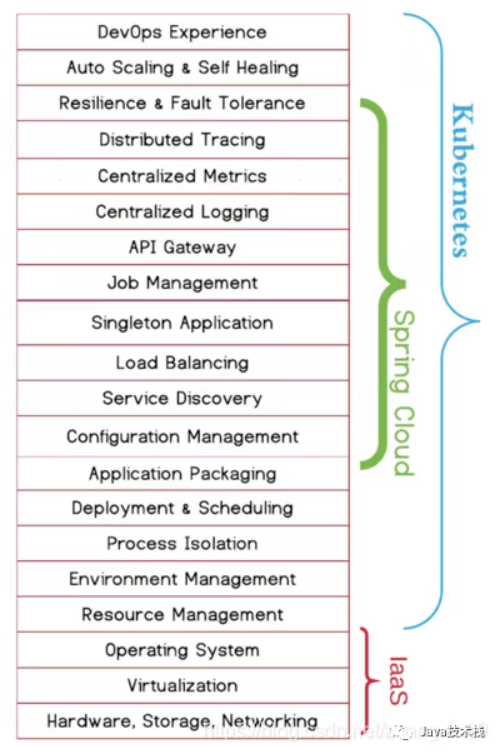
分析下来,可以替换的组件包括网关(gateway 或者 Zuul,由Ingress gateway 或者 egress 替换),熔断器(hystrix,由SideCar替换),注册中心(Eureka及Eureka client,由Polit,SideCar 替换),负责均衡(Ribbon,由SideCar 替换),链路跟踪及其客户端(Pinpoint 及 Pinpoint client,由 SideCar 及Mixer替换)。这是我们在 Spring Cloud 解析中需要完成的目标:即确定需要删除或者替换的支撑模块。
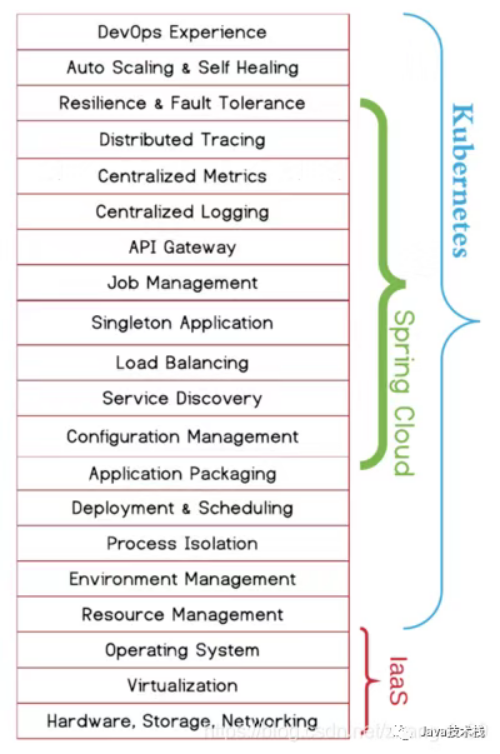
可以说,springcloud关注的功能是kubernetes的一个子集。
可以看出,两边的解决方案都是比较完整的。kubernetes这边,在Istio还没出来以前,其实只能提供最基础的服务注册、服务发现能力(service只是一个4层的转发代理),istio出来以后,具有了相对完整的微服务能力。而spring cloud这边,除了发布、调度、自愈这些运维平台的功能,其他的功能也支持的比较全面。相对而言,云厂商会更喜欢kubernetes的方案,原因就是三个字:非侵入。
平台能力与应用层的解耦,使得云厂商可以非常方便的升级、维护基础设施而不需要去关心应用的情况,这也是我比较看好service mesh这类技术前景的原因。 -
音乐创作编程语言Alda发布在 开源推荐
Alda 是用于音乐创作的基于文本的编程语言,它可以通过在编辑框里输入代码来谱写不同种类的曲子,并且能把这些曲子编译成音乐。使用者通过 Alda 只需文本编辑器和命令行即可编写和播放音乐。Alda 语法简单,初学者很容易就能上手,实际上,Alda 就是为那些没有什么编程经验的人而写的。Alda 的 slogan —— 音乐家使用的编程语言,就说明了这一切。Alda易于理解、类似标记语言的语法,专门面向不知道如何编程的音乐家以及不知道如何作曲的程序员而设计,乐谱是可以使用 alda 命令行工具播放的文本文件,交互式 REPL 可让使用者输入 Alda 代码并实时收听结果,支持以编程方式编写音乐(算法作曲、在线编程等),支持使用 General MIDI Sound Set 中的任何乐器创作 MIDI 音乐。
-
实现将同步变成异步发布在 技术答疑
任何软件问题都可以通过添加一层中间层来解决,如果不能,那就再加一层,同样的针对以上问题我们也可以添加一个中间层来解决,比如添加个队列,把用户注册这个事件放到队列中,让其他模块去这个队列里取这个事件然后再做相应的操作。
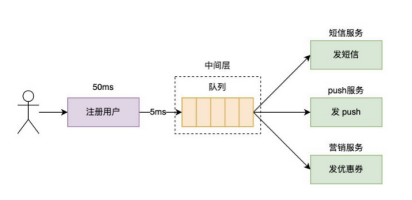
可以看到,这是个典型的生产者-消费者模型,用户注册后只要把注册事件丢给这个队列就可以立即返回,实现了将同步变了异步,其他服务只要从这个队列中拉取事件消费即可进行后续的操作,同时也实现了注册用户逻辑与其他服务的解耦。另外即使流量暴增也没有影响,因为注册用户将事件发给队列后马上返回了,这一发消息可能只要 5 ms,也就是说总耗时是 50ms+5ms = 55 ms,而原来的总耗时是 200 ms,系统的吞吐量和响应速度提升了近 4 倍,大大提升了系统的负责能力,这一步也就是我们常说的削峰,将暴增的流量放入队列中以实现平稳过渡,加了一层队列就达到了异步,解藕,削峰的目的。
由于队列在生产者所在服务内存,其他消费者不得不从生产者中取,也就意味着生产者与消息者紧藕合,这显然不合理。
消息丢失:现在是把消息存储在队列中,而队列是在内存中的,那如果机器宕机,队列中的消息不就丢失了吗,显然不可接受。
单个队列中的消息只能被一个服务消费,也就是说如果某个服务从队列中取消息消费后,其他服务就取不了这个消息了,有一个办法倒是可以,为每一个服务准备一个队列,这样发送消息的时候只发送给一个队列,再通过这个队列把完整消息复制给其他队列即可。
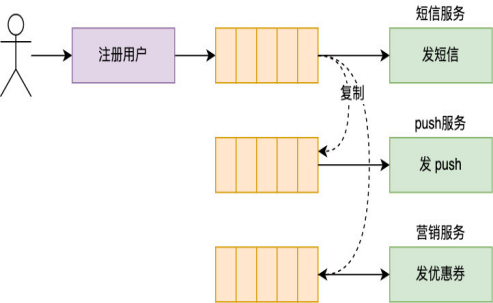
-
可扩展的Web浏览器Next发布在 开源推荐
Next 是一个面向键盘的、可扩展的 Web 浏览器,专为高级用户设计。该应用程序具有键绑定(Emacs,VI),在 Lisp 中是完全可配置和可扩展的,并且对生产专业人员具有强大的功能。特性:选项卡的快速切换;快速导航;历史记录用树结构表示。
项目地址:
https://www.oschina.net/p/next -
实现手机模拟激光笔发布在 极客生涯
随着科技的越来越进步,你是否注意到了,这些年我们越来越少在演讲中看到演讲人用激光笔给观众指示所讲的内容。先说激光笔,激光笔的工作原理是射出一束激光,照射到幕布上并反射到观众的眼睛里,于是大家可以看到一个很亮的红色光点。但现在因为大尺寸屏幕越来越便宜,我们越来越少使用幕布这种传统投影显示设备了,毕竟屏幕的显示效果相比幕布而言要更好。而屏幕为了保证良好的显示效果,往往都会在表面的玻璃上使用大量抗反射技术。这些抗反射技术的运用大大减弱了激光的反射,所以最终用户看到的红色光点就不那么显眼了,激光笔如果使用在这里效果就会大打折扣。
那么有没有可能用大家出门唯一愿意携带的手机来替代激光笔呢?3D 模拟方案:简单来说就是用手机内置的姿态传感器和加速度传感器来构建出手机和显示屏在三维空间中的方位和姿态,再以此模拟计算如果从手机发出一束激光,会照射到屏幕上的哪个位置,并在屏幕上的相应位置绘制一个红点,这样来实现手机模拟激光笔的效果。
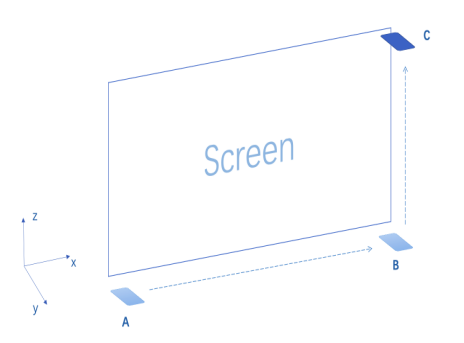
如上图所示,假设一块屏幕的两条邻边分别平行与 X 轴和 Z 轴。当手机从 A 点沿着屏幕的一条边移动到 B 点,再从 B 点沿着屏幕的另一条边移动到 C 点,我们就可以计算出屏幕在以 A 点为原点的三维空间中的具体位置。能够通过把手机从 A 点移动到 B 点和 C 点来计算出屏幕的位置,自然也可以在接下来计算出任意时刻手机相对屏幕的空间位置和姿态方向,并模拟计算从手机射出一束激光会照射到屏幕的哪个位置。
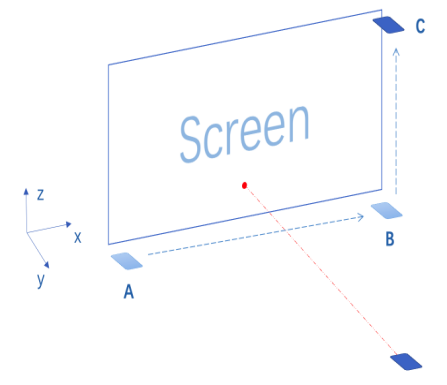
可是,实验过后我发现这个方案虽然在理论上是可行的,但因为累积误差的存在,实际并不可行。
我们拿手机从 A 点移动到 B 点这个最基础的场景来举例。当一个人拿着手机从 A 移动到 B 的时候,手机的加速度、速度和移动距离可以用下面三幅图来描述。
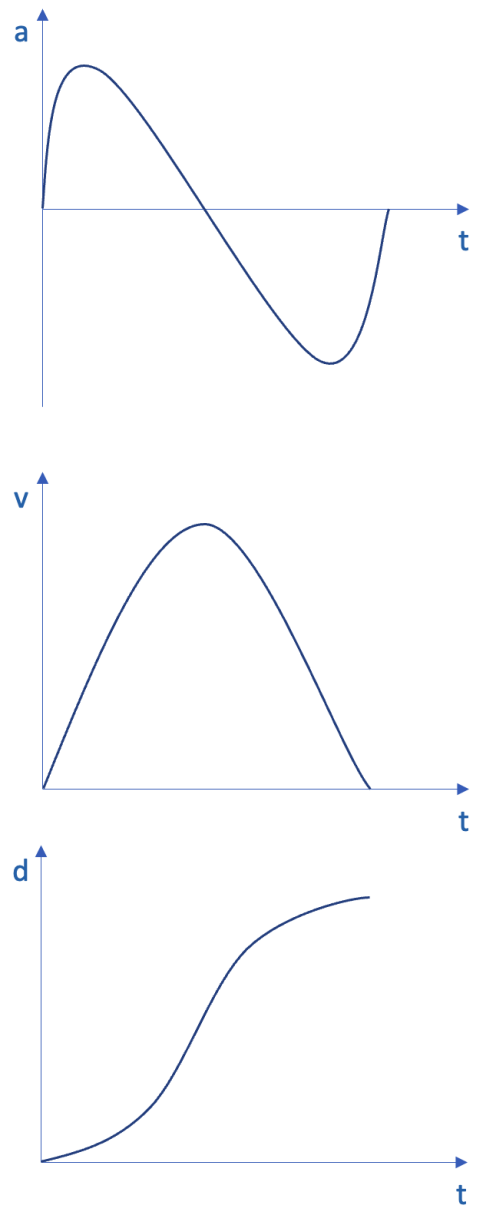
横轴 t 表示时间,纵轴 a、v、d 分别表示手机在 x 方向的加速度、速度和移动距离。
第一幅图中,加速度前半程是正的,后半程是负的,所以手机在 x 方向上先加速后减速,速度从 0 增长到最大,后又慢慢减为 0,而移动距离一开始因为速度比较慢,所以增长慢,中间速度达到最大值,移动距离也增长得最快,最后速度归 0,移动距离也不在增长。
可问题就出在加速度上。本来加速度正的部分的积分和负的部分的积分,也就是蓝色区域的面积和黄色区域的面积,是完全一致的,这样当运动过程结束时手机的速度就会恢复为 0,但实际情况并非如此。 -
纹理合成器发布在 极客生涯
基于判别器和生成器建模方法的纹理合成具有很大的潜力,但是现有方法为了效率而采用的前向网络在泛化能力上并不行,即一个网络只能合成一种纹理,缺少多样性。本文着重解决该问题。训练一个多纹理合成网络存在的一些困难:不同类型纹理的统计特是完全不同,使用基于 Gram 矩阵的纹理损失[1, 2]只能部分的衡量其中的差异;纹理之间内在的不同导致收敛速率也不一样。所以训练一个多纹理合成网络的难度取决于纹理之间的差异和各个纹理本身的复杂性。另外,多纹理合成网络还会出现输入的噪声向量被边缘化的问题,这就导致一个给定的纹理无法生成多个不同样本,这通常意味着对特定纹理的过拟合。
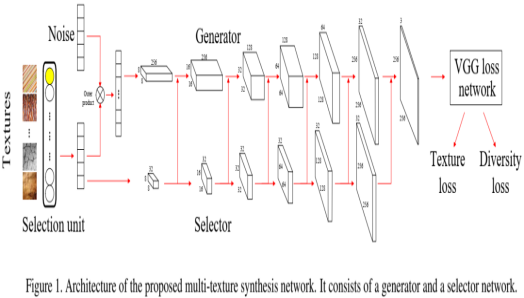
本文设计的网络结构有两个输入,一个噪声向量、一个 one-hot vector 表示不同纹理,网络分为 Generator 和 Selector 两路,Selector 的每层的特征图除了自用之外,还会和 Generator 的对应层特征拼接在一起作为 Generator 下一层的输入,最后一层的输出即为生成的纹理,再使用 VGG 提取特征。基于 Gram 矩阵的纹理损失函数对于单一纹理合成很有用,但是用于多纹理时并不够理想,作者认为这是因为不同纹理的 Gram 矩阵在尺度上有较大的差异导致的,所以本文首先是改进了 Texture loss,由公式(1)变成公式(2):
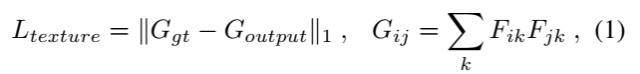
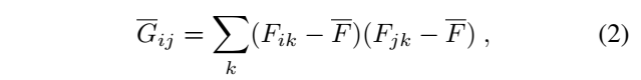
改进前后的效果对比:

第一行是原始纹理,第二行是公式(1)的效果,第三行是改进后的效果。 -
多媒体播放器ubuntu-xplay发布在 开源推荐
ubuntu-xplay 是一个十分易上手的多媒体播放器。能够同时支持视频、音频、流媒体、图片、摄像头、动画、文本、滚动字幕、日期时间、二维码,还能够支持自定义播放器分辨率、帧率(FPS),支持音频采样率(Sample Rate)自适应。支持使用(TCP)连接播放器发送指令控制,播放、覆盖、停止、移动等操作;支持视频、音频、流媒体、图片、摄像头、动画、文本、滚动字幕、日期时间、二维码等多种格式的素材播放;视频类型也支持很多种类:例如:MP4格式、AVI、MOV等,音频AAC;
支持各种种类的图片类型:支持视频单线程解码与多线程解码双模式;支持视频、图片等无黑场切换播放;支持视频、流媒体、图片、摄像头、动画、文本、滚动字幕、日期时间、二维码等多层Overlay播放;支持自定义各种文本方式;支持滚动字幕自定义播放;支持信息提示框自定义提示文本及多种状态标识;支持日期时间自定义;
支持自定义布局,可以通过多层功能可以实现多种自定义布局;支持自定义视频是否循环播放,视频在播放到结尾时是否停留在最后一帧;支持自定义素材尺寸,可以任意拉伸缩放素材尺寸播放;能够自定义素材位置播放,任意定义素材播放位置;还可以任意移动素材位置及改变素材尺寸;支持自定义素材横竖屏旋转,使用十分的自由;支持自定义素材开始播放时间,多个播放器间可以实现同步播放;支持实时屏幕快照或者截屏;支持静音播放。
-
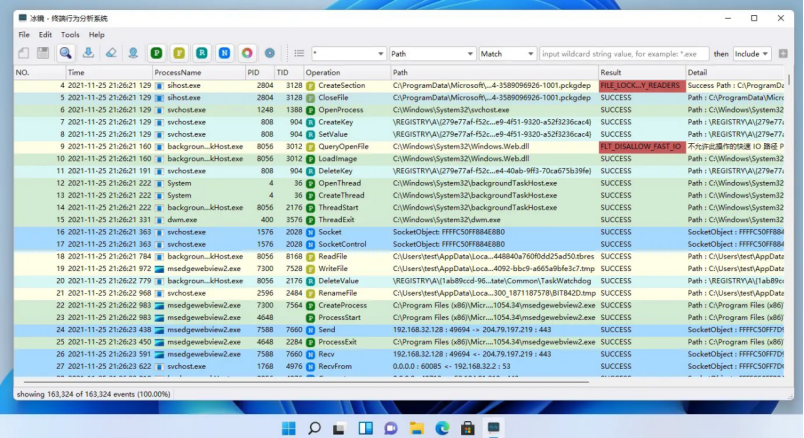
终端行为分析系统 iMonitor-冰镜发布在 开源推荐
iMonitor(冰镜 - 终端行为分析系统)(开源版本 Procmon)是一款基于 iMonitorSDK 的开源终端行为监控分析软件。提供了对进程、文件、注册表、网络等系统行为的监控。支持扩展和脚本,可以轻易定制和添加更多功能。可以用于病毒分析、软件逆向、入侵检测,EDR等。
-
web实现人脸识别发布在 极客生涯
整个功能的逻辑很简单,前端调起摄像头,识别到人脸后拍照上传到后台,后端SDK识别出图片中的人脸特征后,与数据库内的用户人脸特征做比对,比对成功(相似度在0.8~1之间即算同一个人)登录,如识别到人脸但数据库内未比对成功则视为新用户注册。
要注意如果要在线上应用,必须要使用https才能调起摄像头,本地测试没有限制。
整体流程的线上预览地址是:https://fire100.top,大家预览的时候可以放心,不会真的收集面部图片,只是提取了面部特征,并没有上传云端。
启动项目之前先做一点准备工作,因为使用的是三方的人脸识别SDK,所以要先在平台申请一个账号,然后在下载对应版本的SDK。
目前支持Linux、Windows、IOS、Android版本,每个实名认证的账号可以激活100台设备,换句话说就是同一个账号申请的SDK可以在100个设备上运行,一般情况下够用了。
-
实时语音克隆Mocking Bird发布在 开源推荐
Mocking Bird 是一个实时语音克隆项目,可在 5 秒内克隆声音并生成任意语音内容。支持普通话并使用多种中文数据集进行aidatatang_200zh,magicdata,aishell3,biaobei,MozillaCommonVoice,data_aishell 等,适用于 Pytorch,已在 1.9.0 版本(最新于 2021 年 8 月)中测试,GPU Tesla T4 和 GTX 2060,可在 Windows 操作系统和 linux 操作系统中运行(苹果系统M1版也有社区成功运行案例)、仅需下载或新训练合成器(synthesizer)就有良好效果,复用预训练的编码器/声码器,或实时的HiFi-GAN作为vocoder,可将训练结果保存在服务器端,供远程调用。
项目地址:
https://www.oschina.net/p/mocking-bird -
手游智能反外挂系统发布在 开源推荐
基于独创源码虚拟化技术打造智能反外挂系统,帮助国内外游戏抵抗外挂、盗版、资源窃取等风险。
手游智能反外挂系统是一款针对Unity3D/Cocos2d等手游的安全加固产品,其智能检测机制经过多年迭代更新,具备精准识别外挂、修改器、加速器、模拟器、自动化脚本等风险行为,其次自身安全采用源码虚拟化技术进行高强度加密保护,能完全避免反外挂程序被逆向分析。已为国内外众多游戏提供安全赋能,保障游戏的正常运营和高额营收。
功能特点:防通用修改器:采用独创技术精准识别修改器、加速器、同步器、多开器等外挂及变种,一旦发现将立即闪退。

防模拟器运行:采用底层技术精准识别市面所有模拟器,打击作弊、自动化挂机等行为,一旦发现将立即闪退。

防虚拟机运行:精准识别游戏在VirtualAPP、平行空间等虚拟机中运行,则立即闪退。

防动态调试:集成反调试【Java/C/C++】、内存保护、等功能,游戏运行时进行主动防御。

防资源窃取:对U3D AssertBundle、U3D和Cocos2D静态资源进行安全加密,防止美术资源被非法窃取。自身虚拟化保护:智能反外挂系统自身采用源码虚拟化加密技术保护,防止攻击者逆向分析反外挂系统的业务逻辑。 -
人工智能音乐研究 Muzic发布在 开源推荐
音乐在人类的社会与人类是密不可分的,音乐一直是人类表达情感的一个载体。从古代人们务农时唱的山歌到现在的古典音乐,流行音乐。音乐对人们的影响源源不断 Muzic 是一个人工智能音乐研究项目,通过深度学习和人工智能赋能音乐理解和生成。Muzic 发音为 [ˈmjuːzeik]。
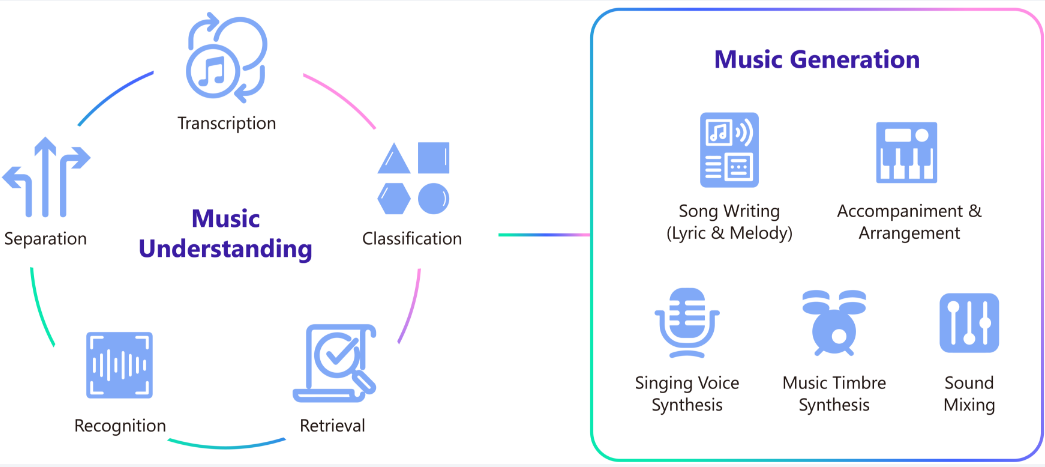
Muzic 目前的工作包括:音乐理解:符号音乐理解:MusicBERT;自动歌词转录:PDAugment音乐生成:歌曲创作:SongMASS;歌词生成:DeepRapper旋律生成:TeleMelody;伴奏生成:PopMAG;歌声合成:HiFiSinger。

项目地址:
https://gitee.com/mirrors/muzic -
分布式事物—TCC发布在 极客生涯
在电商领域等互联网场景下,传统的事务在数据库性能和处理能力上都暴露出了瓶颈。在分布式领域基于CAP理论以及BASE理论,有人就提出了柔性事务的概念。在业内,关于柔性事务,最主要的有以下四种类型:两阶段型、补偿型、异步确保型、最大努力通知型几种。我们前边讲过的2PC和3PC都属于两阶段型,两阶段型事务存在长期锁定资源的情况,导致可用性差。接下来我们来介绍的TCC则是补偿型分布式事务。
TCC方案是可能是目前最火的一种柔性事务方案了。关于TCC(Try-Confirm-Cancel)的概念和解释,最早是在Pat Helland于2007年发表的一篇名为《Life beyond Distributed Transactions:an Apostate’s Opinion》的论文中提出的。在该论文中,TCC还是以Tentative-Confirmation-Cancellation命名。正式以Try-Confirm-Cancel作为名称的是Atomikos公司,其注册了TCC商标。国内最早关于TCC的报道,应该是InfoQ上对阿里程立博士的一篇采访。经过程博士的这一次传道之后,TCC在国内逐渐被大家广为了解并接受。
TCC将事务提交分为Try-Confirm-Cancel 3个操作。
Try:预留业务资源/数据效验;
Confirm:确认执行业务操作;
Cancel:取消执行业务操作。TCC事务处理流程和 2PC 二阶段提交类似,不过2PC通常都是在跨库的DB层面,而TCC本质就是一个应用层面的2PC。
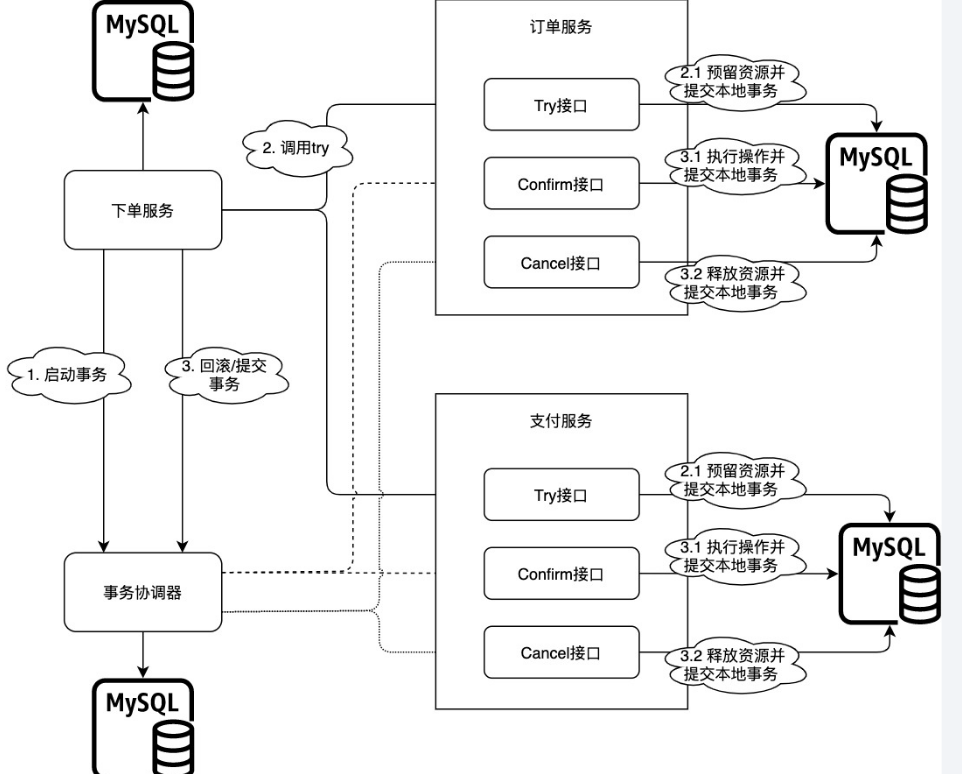
-
Tomcat服务器发布在 极客生涯
tomcat作为一个 Web 服务器,实现了两个非常核心的功能:Http 服务器功能:进行 Socket 通信(基于 TCP/IP),解析 HTTP。Servlet 容器功能:加载和管理 Servlet,由 Servlet 具体负责处理 Request 请求。
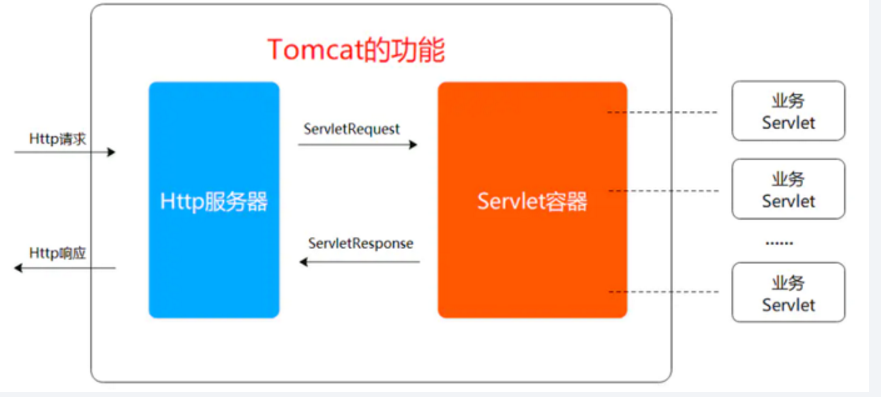
以上两个功能,分别对应着tomcat的两个核心组件连接器(Connector)和容器(Container),连接器负责对外交流(完成 Http 服务器功能),容器负责内部处理(完成 Servlet 容器功能)。
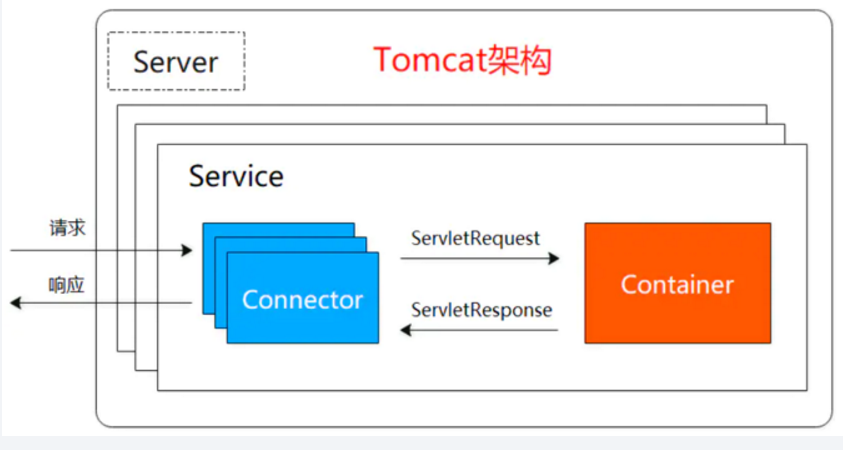
Server:Server 服务器的意思,代表整个 tomcat 服务器,一个 tomcat 只有一个 Server Server 中包含至少一个 Service 组件,用于提供具体服务。Service:服务是 Server 内部的组件,一个Server可以包括多个Service。它将若干个 Connector 组件绑定到一个 Container。
Connector:称作连接器,是 Service 的核心组件之一,一个 Service 可以有多个 Connector,主要连接客户端请求,用于接受请求并将请求封装成 Request 和 Response,然后交给 Container 进 行处理,Container 处理完之后在交给 Connector 返回给客户端。
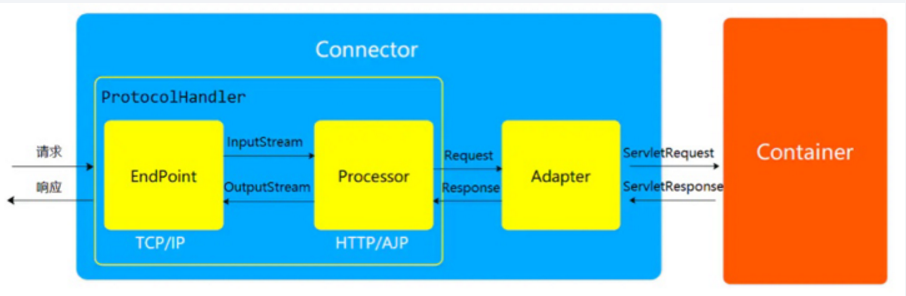
Container:负责处理用户的 servlet 请求。 -
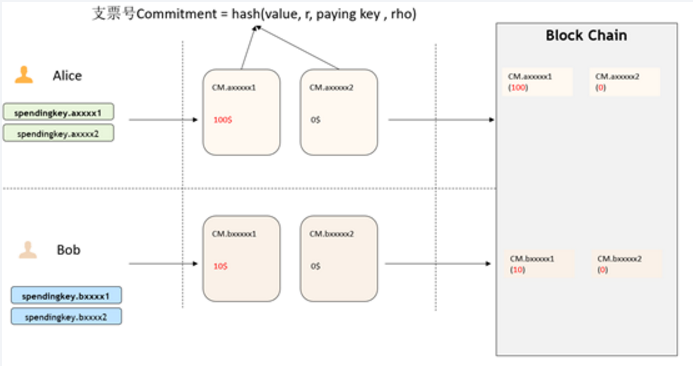
什么是zk-snark发布在 极客生涯
zk-SNARK 是 Zero-knowledge succinct non-interactive arguments of knowledge 的缩写,翻译为中文则表示零知识,即在证明的过程中不透露任何隐私数据: succinct:简洁的,主要是指验证过程不涉及大量数据传输以及验证算 法简单; non-interactive:无交互。证明者与验证者之间不需要交互即可实现证 明,交互的零知识证明要求每个验证者都要向证明者发送数据来完成证明, 而无交互的零知识证明,证明者只需要计算一次产生一个 proof,所有的验 证者都可以验证这个 proof。 zk-SNARK 是证明某个声明是真却不泄露关于该声明的隐私信息的一 个很有创新性的算法,他可以证明某人知道某个秘密却不会泄露关于这个 秘密的任何信息。
Zcash是zk-SNARKs的第一个广泛应用,zk-SNARKs是一种新颖的零知识密码学形式。Zcash的强大隐私保证源于Zcash中的屏蔽事务可以在区块链上完全加密,但仍然可以通过使用zk-SNARK证明在网络共识规则下验证为有效。
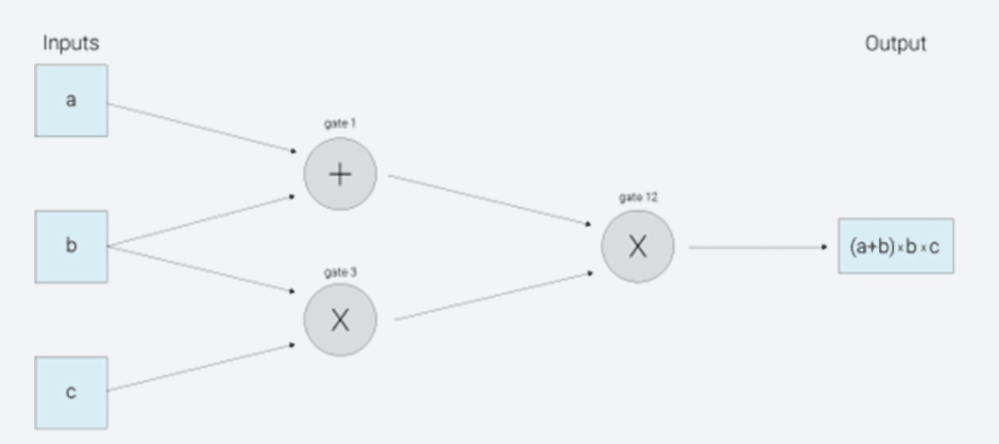
它是对所有零知识证明问题的通用解决方法,由加密数字货币zcash首次使用并开源。zk-SNARK的优点:拥有通用库,可以解很多零知识证明问题;验证证明性能较高。但是zk-SNARK也有不足之处,比如.底层模型不容易理解,用户需要根据具体的零知识证明问题,在上层构建自己的业务模型,这块开发的工作量较大。生成每笔交易时延较长。
应用场景ZKP的应用场景包括匿名可验证投票、数字资产安全交换、安全远程生物识别认证和安全拍卖等各个场景。
零知识证明是指一方(证明者)向另 一方(验证者)证明一个陈述是正确的, 而无需透露除该陈述正确以外的任何信 息,适用于解决 任 何NP问题。而区块 链 恰好可以抽象成多方验证交易是否有效 (NP问题)的平台,因此,两者是天然相 适 应的。将零知识证明应用到区块 链中 需要考虑的技术挑战分为两大类:一类是适用于隐私保护的区块链架构设计方 案,包括隐秘交易所花资产存在性证明、匿名资产双花问题、匿名资产花费与转移、隐秘交易不可区分等技术挑战;另一类是零知识证明技术本身带来的挑战,包括参数初始化阶段、算法性能以及安全问题等技术挑战。