流计算和批处理summingbird
-
twitter 开源了summingbird ,一个流计算和批处理模式的融合体,用户编写的逻辑既可以运行在 Storm 上,也可以跑在#Hadoop#上,将来还计划支持Spark。听说是#storm#和hadoop的合体。雅虎也有类似的开源产品 #storm-yarn#。
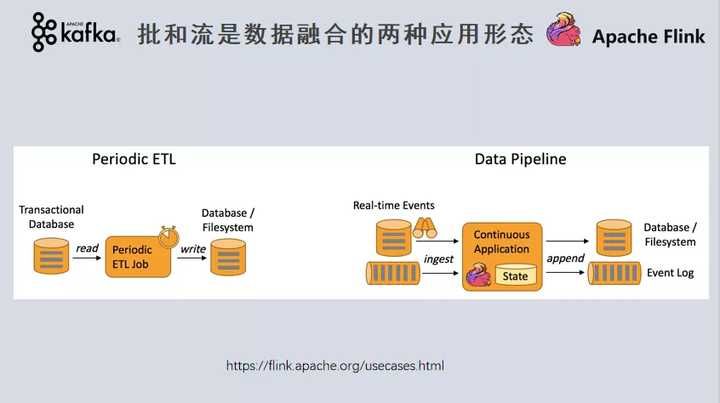
传统的数据融合通常基于批模式。在批的模式下,我们会通过一些周期性运行的ETL JOB,将数据从关系型数据库、文件存储向下游的目标数据库进行同步,中间可能有各种类型的转换。
另一种是Data Pipeline模式。与批模式相比相比, 其最核心的区别是将批量变为实时:输入的数据不再是周期性的去获取,而是源源不断的来自于数据库的日志、消息队列的消息。进而通过一个实时计算引擎,进行各种聚合运算,产生输出结果,并且写入下游。现代的一些处理框架,包括Flink、Kafka Streams、Spark,或多或少都能够支持批和流两种概念。只不过像Kafka,其原生就是为流而生,所以如果基于Kafka Connect做批流一体,你可能需要对批量的数据处理做一些额外工作,这是我今天重点要介绍的。
项目地址: https://github.com/twitter/summingbird

西南地区IT社群(QQ)
- 云南
- 【昆明网页设计交流吧】243627302
- 【昆明nodejs交流吧】 243626749
- 【VUE】838405306
- 【云南程序员总群】343606807
- 【昆明UI设计】104031254
- 【云南软件外包】15547313
- 贵州
- 【PHP/java源码/站长交流群】55692114
- 四川
- 【成都Java/JavaWeb交流】86669225
- 【vaScript+PHP+MySql】116270060
- 【UI设计/设计交流学习群】135794928
- 重庆
- 【诺基亚 JAVA游戏博物馆】 559479780
- 【PHP,Java,Python,C++接单】 442103442
- 西藏