InvenTree 是一个开源库存管理系统,提供强大的低级库存控制和零件跟踪。InvenTree 系统的核心是一个 Python/Django 数据库后端,它提供了一个管理界面(基于 Web)和一个用于与外部界面和应用程序交互的 REST API。
InvenTree 设计为轻量级且易于使用,适用于 SME 或业余爱好者应用程序,在这些应用程序中,许多现有的库存管理解决方案都臃肿且难以使用。更新库存是一个单操作过程,不需要复杂的工作订单或库存交易系统。强大的业务逻辑在后台运行,以确保维护库存跟踪历史记录,并且用户可以随时访问库存级别信息。
卫恩赋 发布的帖子
-
开源库存管理系统InvenTree发布在 开源推荐
-
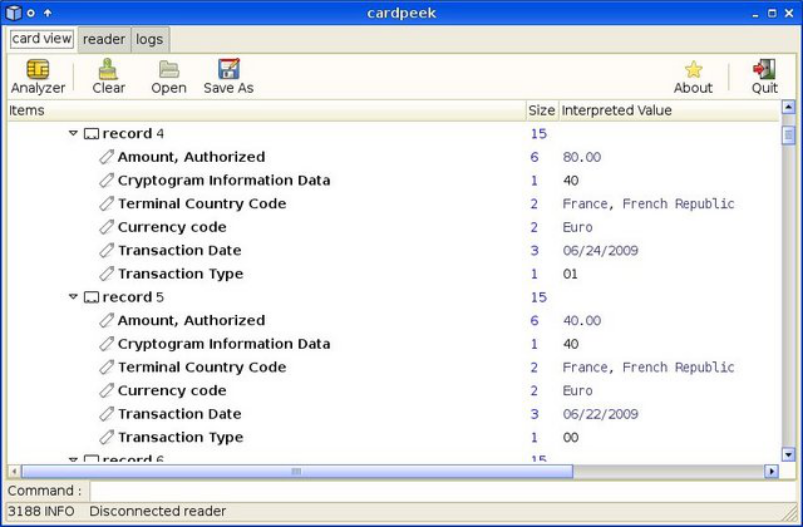
ISO7816 智能卡读取工具Cardpeek发布在 开源推荐
Cardpeek 是个读取 ISO7816 智能卡内容的工具。它主要提供一个 GUI ,用树视图来展示卡数据,并且可以用 LUA 脚本语言来扩展。这个项目主要是为了让智能卡用户更好的了解哪些个人信息类型存储在这个设备上。这个工具目前能读取的有: EMV 银行卡,Calypso 公交卡 (比如 Navigo, RavKav 和 Mobib),比利时 eID 卡, GSM SIM 卡, 法国 Vitale 2 健康卡,一些 Mifare 卡和 Moneo 电子钱包卡。
-
在DOS上运行Linux程序doslinux发布在 开源推荐
DOS Subsystem for Linux(DSL)是为喜欢 MS-DOS 环境的用户提供的 WSL 选择。DOS Subsystem for Linux 将真实的 Linux 环境集成到 MS-DOS 系统中,允许用户从 DOS 命令提示符中同时使用 DOS 和 Linux 应用程序。
Building在 PATH 上有一个针对 i386-linux-musl 的交叉工具链。通过运行 J=xxx script/build-prereq 来构建先决条件(Linux 和 Busybox),将 xxx 替换为所需的 build parallelism。获取硬盘镜像 hdd.base.img,并在第一个分区上安装 MS-DOS 的副本。运行 make(这将创建一个新的硬盘镜像 hdd.img,并安装 DOS Subsystem for Linux);调用 C:\doslinux\dsl <command> 来运行 Linux 命令(也可以将 C:\doslinux 放在你的 DOS PATH 上,这样会更方便)。目前,DSL 已经在 MS-DOS 6.22 和 FreeDOS 中进行了尝试。 -
WSL2内核源码WSL2-Linux-Kernel发布在 开源推荐
WSL2-Linux-Kernel 基于 Linux 内核修改而来,是微软 WSL 2 使用的内核源码。与第一代相比,WSL 2 重新设计了架构,使用真正的 Linux 内核,支持在 Windows 上运行 ELF64 Linux 二进制文件。第一代 WSL 只是提供了等价的 Linux API,性能比原生 API 差很多,而 WSL 2 使用 Hyper-V 创建一个轻量级虚拟机运行真正的 Linux 内核,具有完整的系统调用兼容性,速度也明显比第一代更快。按照 Linux 内核使用的 GPLv2 开源许可证要求,微软需要公布它修改的内核源代码。
-
自定义对象检测和分类训练Cloud Annotations发布在 开源推荐
Cloud Annotations 是一种快速、轻松、协作式的开源图像标注工具,用于自定义对象检测和分类训练。它使用 AI 帮助开发人员标注数据,而不必在整个图像数据集上手动绘制标签。只需从仪表板上选择 “自动标签”(Auto label)按钮,即可自动为上传的图像样本添加标签。
Cloud Annotations 使用户可以存储所需数量的数据,从任何地方访问数据,并在多个协作者之间实时共享。 -
机器学习可解释性InterpretML发布在 开源推荐
InterpretML 是一个开源软件包,整合了最先进的机器学习可解释性技术。使用此包,你可以训练可解释的 glassbox 模型并解释黑盒系统。InterpretML 可帮助你了解模型的全局行为,或了解个别预测背后的原因。优点:模型可解释性可帮助组织中的开发人员、数据科学家和业务利益相关者全面了解他们的机器学习模型。它还可以用于调试模型、解释预测并启用审计以满足法规要求。通过开放的统一 API 集和丰富的可视化访问最先进的可解释性技术。使用各种解释器和使用交互式视觉效果的技术来理解模型。选择您的算法并轻松尝试算法组合。探索模型属性,例如性能、全局和局部特征,并同时比较多个模型。在操作数据并查看对模型的影响时运行假设分析。
-
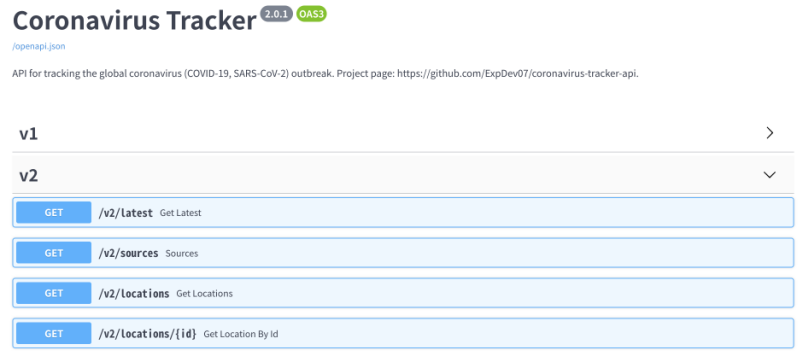
跟踪新冠病毒感染情况的API Coronavirus Tracker API发布在 开源推荐
Coronavirus Tracker API 是一个简单并且十分快捷的API,被用于跟踪全球新冠病毒(SARS-CoV-2)的感染情况,包括有关确诊病例、死亡人数和康复人数都能够实时更新。Coronavirus Tracker API使用 FastAPI 框架编写而成,响应时间 <200ms,同时能够支持多种数据来源。
-
云端原生大数据引擎发布在 极客生涯
MatrixOne 是一个行星级的云端原生大数据引擎,专为异构工作负载而设计。它提供了一个端到端的数据处理平台,具有高度的自主性和易用性,使用户能够跨设备、边缘和云来存储、处理和分析数据,并将操作费用降到最低。MatrixOne 集群可以在 SQL 处理、计算和存储过程中通过动态向集群添加节点来轻松扩展容量。MatrixOne 不仅限于公共云、混合云、内部部署服务器或智能设备,它可以适应无数的基础设施,同时仍然提供低延迟和高吞吐量的顶级服务。
通过融合多个引擎,MatrixOne 可以支持混合流、事务和分析工作负载;凭借其可插拔架构,MatrixOne 允许与第三方引擎轻松集成。MatrixOne 使用基于 RAFT 的共识算法在一个区域内提供容错。并且未来计划使用更高级的状态机复制协议来实现地理分布式双活。MatrixOne 的一个重要目标是让用户可以轻松操作和管理数据,让日常工作几乎不费吹灰之力。通过流式传输 SQL 和用户定义的函数,MatrixOne 提供端到端的数据处理管道,以交付高效的数据科学应用程序。
-
Rust实现分布式计算框架发布在 开源推荐
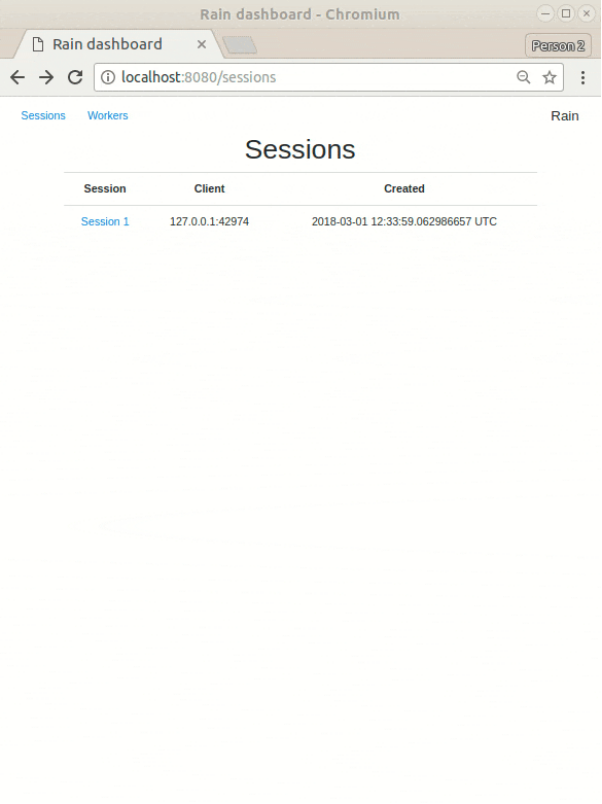
Rain 是一个 Rust 实现的轻巧且强大的分布式计算框架,适用于处理大规模的基于任务的管道。Rain 旨在降低分布式计算世界的入门门槛,目的是提供一个轻巧而强大的分布式框架,该框架具有直观的 Python API、简单的安装和部署以及顶层的深入监控。数据流编程:Rain 中的计算被定义为任务的流程图(flow graph)。任务可以是内置函数,Python/C++/Rust 代码,也可以是外部应用程序,短而轻或长时间运行且繁重。该系统旨在将任何代码集成到管道中,合理分配其资源需求,并处理非常大的任务图(task graphs),通常是数十万个任务。
易于使用:Rain 设计之初就考虑到要易于部署,从单节点部署到大规模分布式系统和数千个核心的云。
Rust 核心:Python/C++/Rust API。为了安全和高效,Rain 采用 Rust 编写,并为 Rain 核心基础架构提供了高级 Python API,甚至支持开箱即用的 Python 任务。Rain 还提供了用 C++ 和 Rust 编写自己的任务的库。
监控:支持在线和 postmortem 监控。 -
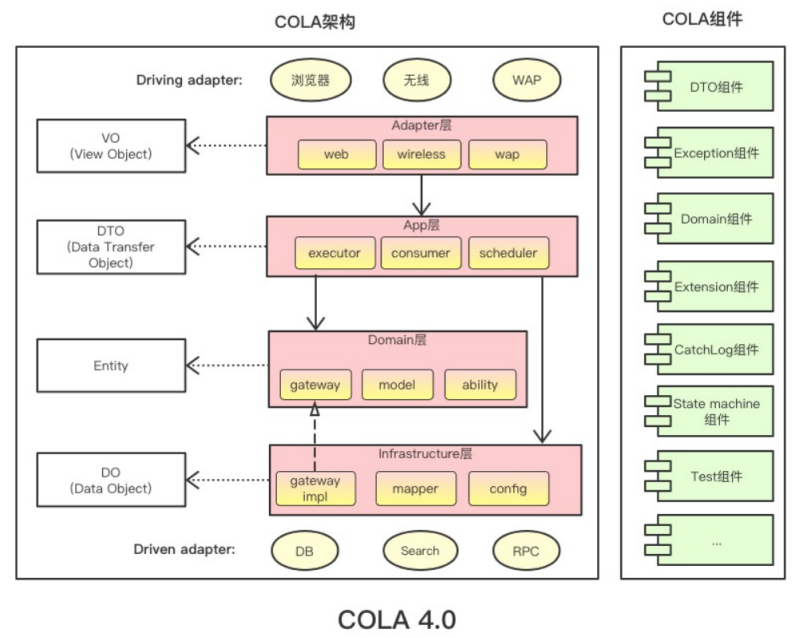
整洁面向对象分层架构COLA Architecture发布在 开源推荐
领域驱动设计DDD最大的好处是将业务语义显现化,把原先晦涩难懂的业务算法逻辑,通过领域对象、统一语言将领域概念清晰的显性化表达出来。
如果整个系统都采用DDD进行领域建模,不仅代码的可读性和系统的可维护性会大大提升,系统之间的边界和交互也会更加的清晰。
COLA是一个面向对象的分层框架,它是Clean Object-Oriented and Layered Architecture的缩写,代表的意思是“整洁面向对象分层架构”。分为两个部分,COLA 架构和 COLA 组件。
-
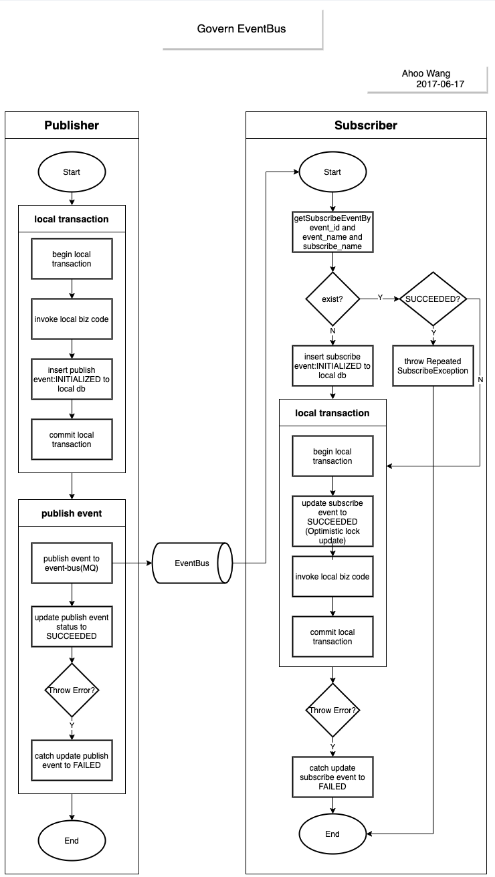
事件驱动架构框架Govern EventBus发布在 开源推荐
Govern EventBus 架构框架是一个历经四年生产环境验证的事件驱动架构框架,它定义了一个设计和能够实现一个应用系统的方法学,在这个系统里事件可传输于松散耦合的组件和服务之间。
它是通过事件总线机制来治理微服务间的远程过程调用。能够使用本地事务来支持微服务内强一致性,事件总线来实现微服务间的最终一致性,还另外提供了事件发布/订阅失败的自动补偿机制。
项目地址:
https://www.oschina.net/p/govern-eventbus -
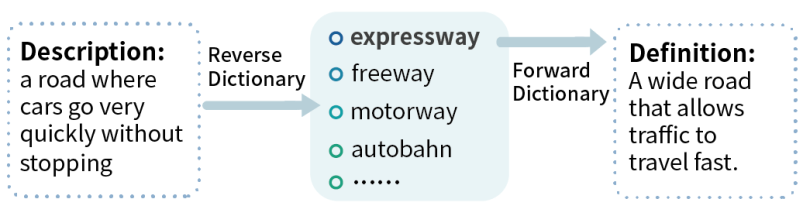
在线反向词典WantWords发布在 开源推荐
WantWords 是一个由清华大学自然语言处理实验室出品的开源在线反向词典。与为查询词提供定义的常规(正向)词典相反,反向词典返回与查询描述语义相符的词。解决表述问题,即无法从记忆中检索出一个词的现象,帮助新的语言学习者,帮助选词(或词库)失忆症患者,这些人能够识别和描述一个物体,但由于神经系统紊乱而不能说出它的名字。
项目地址:
https://www.oschina.net/p/wantwords -
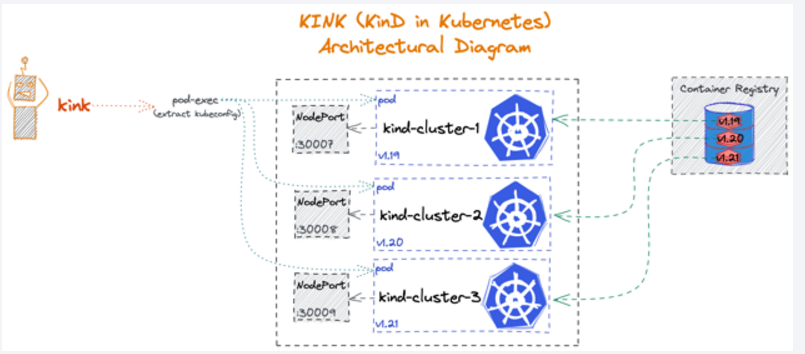
KinD 集群管理工具 KinK发布在 开源推荐
KinD 是一个使用 Docker 容器运行本地 Kubernetes 集群的工具,主要目的是用来测试,但也可用于本地开发。Kink 是一个 CLI 应用程序,它可以直接在 Kubernetes 集群的 Pod 中运行 KinD 集群,并管理 KinD 集群的生命周期。
kind 是另一个 Kubernetes SIG 项目,但它与 minikube 有很大区别。它可以将集群迁移到 Docker 容器中,这与生成虚拟机相比,启动速度大大加快。简而言之,kind 是一个使用 Docker 容器节点运行本地 Kubernetes 集群的工具(CLI)。
kind经过 CNCF 认证,并且支持多节点集群,包括高可用集群。并且支持 Linux、macOS 以及 Windows 操作系统,操作简单,学习成本低,非常适合用来在本地搭建基于 Kubernetes 的开发/测试环境。
-
工作负载资源之deployment发布在 极客生涯
首先我们需要理解:一个应用跑在k8s集群上了,那么这个应用就是一个工作负载(workloads)。在k8s中会用pod的来承载这个应用,那么负责管理这个pod的东西就叫工作负载资源(workload resources)。
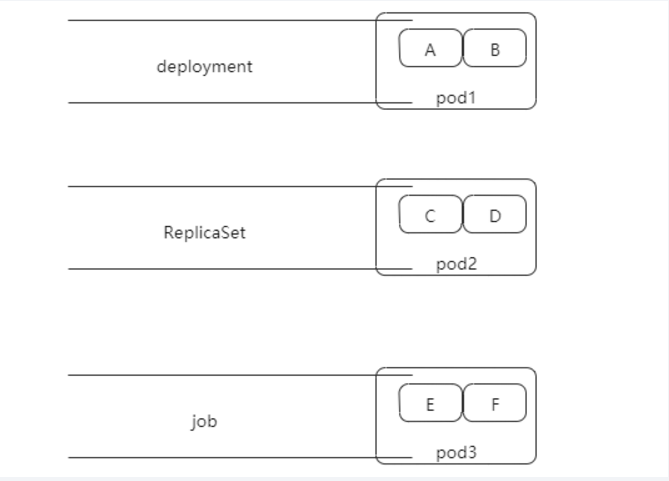
一个 Deployment 为 Pods和 ReplicaSets提供声明式的更新能力,我们要从接下来的几个方面开始上手:首先需要创建 Deployment 将 ReplicaSet 上线。 ReplicaSet 在后台创建 Pods。 检查 ReplicaSet 的上线状态,查看其是否成功。之后通过更新 Deployment 的 Pod模板(TemplateSpec),声明 Pod 的新状态 。 **新的 ReplicaSet 会被创建,Deployment 以受控速率将 Pod 从旧 ReplicaSet 迁移到新 ReplicaSet。 每个新的 ReplicaSet 都会更新到 Deployment 的修订版本。
如果 Deployment 与你的预期不符,可以回滚到较早的 Deployment 版本。 每次回滚都会更新到 Deployment 修订的新版本。
通过Deployment 扩大应用规模承担更多负载。暂停 Deployment ,对 PodTemplateSpec 做修改然后恢复执行,让pod更新到新版本。
-
MRS-ClickHouse构建用户画像系统发布在 极客生涯
在移动互联网时代,用户数量庞大,标签数量众多,用户标签的数据量巨大。用户画像系统中,对于标签的存储和查询,不同的企业有不同的实现方案。当前主流的实现方案采用ElasticSearch方案。但基于ElasticSearch构建用户画像平台,往往面临灵活性不足、资源开销大、无SQL接口开发不便等问题。为此,本文提供了一种基于华为MRS ClickHouse构建用户画像系统的方法。
用户画像是对用户信息的标签化。用户画像系统通过对收集的各维度数据,进行深度的分析和挖掘,给不同的用户打上不同的标签,从而刻画出客户的全貌。通过用户画像系统,可以对各个用户进行精准定位,从而将其应用于个性化推荐、精准营销等业务场景中。用户画像系统已经被各个企业广泛采用,是大数据落地的重要方式之一。
在移动互联网时代,用户数量庞大,标签数量众多,用户标签的数据量巨大。用户画像系统中,对于标签的存储和查询,不同的企业有不同的实现方案。当前主流的实现方案采用ElasticSearch方案。但基于ElasticSearch构建用户画像平台,往往面临灵活性不足、资源开销大、无SQL接口开发不便等问题。为此,本文提供了一种基于华为MRS ClickHouse构建用户画像系统的方法。
MRS-ClickHouse是一款面向联机分析处理的列式数据库。其最核心的特点是极致压缩率和极速查询性能。MRS-ClickHouse支持SQL查询,且查询性能好,特别是基于大宽表的聚合分析查询性能非常优异,比其他分析型数据库速度快一个数量级。
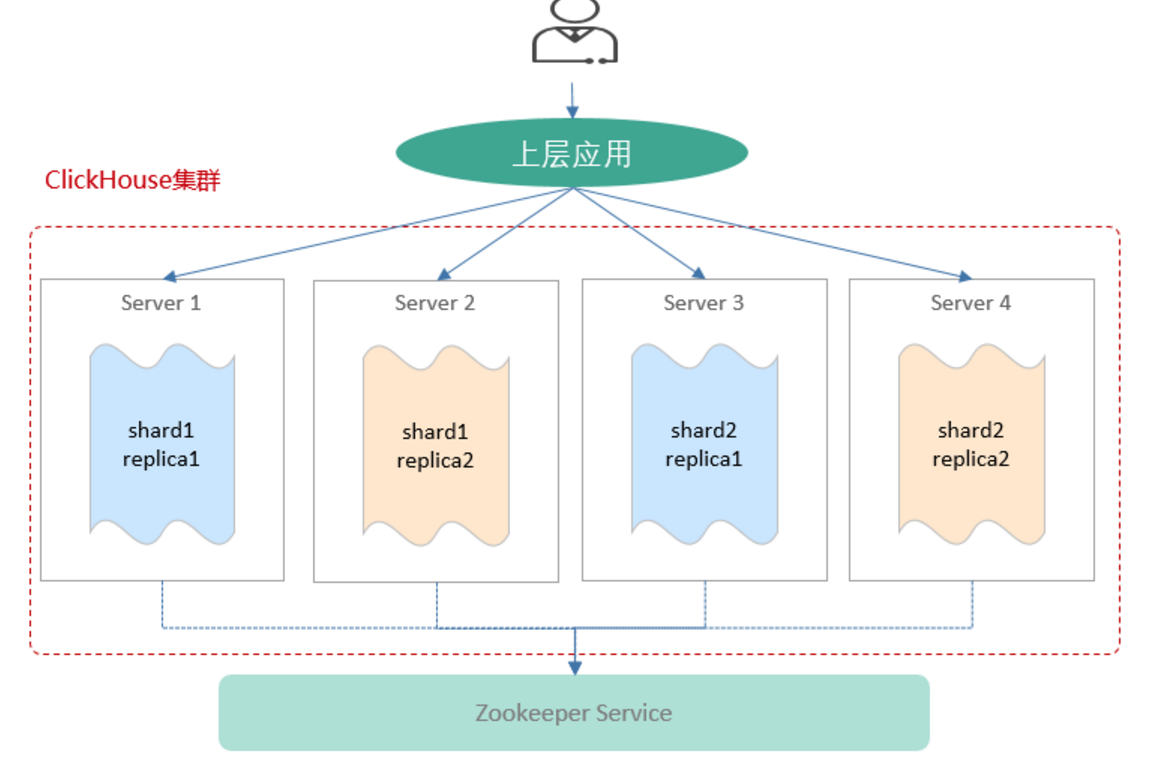
ClickHouse有如下特点:
完备的DBMS功能:ClickHouse拥有完备的数据库管理功能,具备一个DBMS基本的功能,包括DDL、DML、权限控制、数据备份与恢复、分布式管理。列式存储与数据压缩:ClickHouse是一款使用列式存储的数据库,数据按列进行组织,属于同一列的数据会被保存在一起,列与列之间也会由不同的文件分别保存。在执行数据查询时,列式存储可以减少数据扫描范围和数据传输时的大小,提高了数据查询的效率。
向量化执行引擎:ClickHouse利用CPU的SIMD指令实现了向量化执行。SIMD的全称是Single Instruction Multiple Data,即用单条指令操作多条数据,通过数据并行以提高性能的一种实现方式,它的原理是在CPU寄存器层面实现数据的并行操作。
关系模型与SQL查询:ClickHouse完全使用SQL作为查询语言,提供了标准协议的SQL查询接口,使得现有的第三方分析可视化系统可以轻松与它集成对接。同时ClickHouse使用了关系模型,所以将构建在传统关系型数据库或数据仓库之上的系统迁移到ClickHouse的成本会变得更低。
数据分片与分布式查询:ClickHouse集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限取决于节点数量(1个分片只能对应1个服务节点)。
ClickHouse提供了本地表 (Local Table)与分布式表 (Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
-
在eclipse引用本地插件的方法发布在 极客生涯
在eclipse中实现本地插件的引用,这件事情可以说是比较冷门,因为在实际开发中它是属于非必须根本不会使用的一项技能,首先呢我们需要了解一下怎么看装了的插件,要看Help下的About Eclipse,然后再打开左下角Installation Deatils,就可以看已经装了什么插件。

第一种方法:打开本地插件中的features 文件夹和plugins文件夹,并且把两个文件夹的文件分别复制到eclipse解压以后的文件夹下的features 和plugins里面,然后重启eclipse。第二种方法:这种方法可以用eclipse操作,首先需要打开help,之后第一步需要点击add;第二步点击local;第三步点击你的路径;第四步输入name:之后第五步点击install new software之后点完ok,就可以在name看到插件,然后点击选中,再点击select all,然后就下一步,最后完成即可。
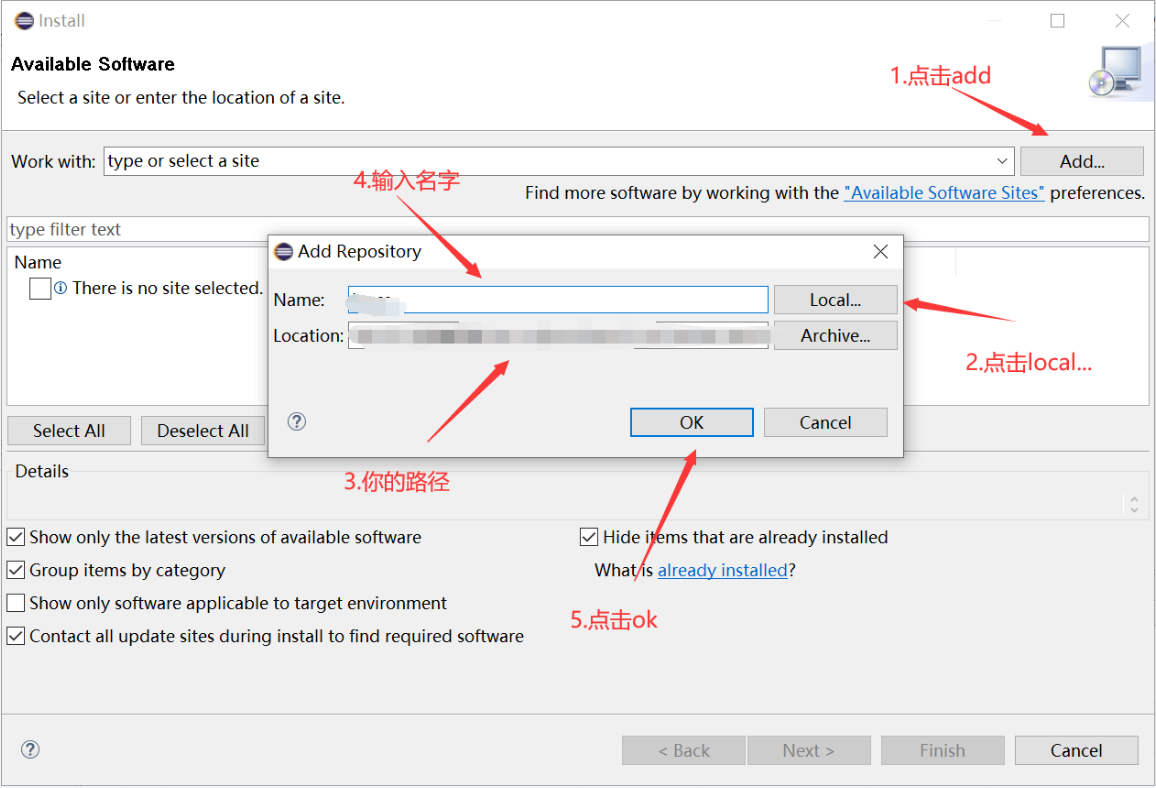
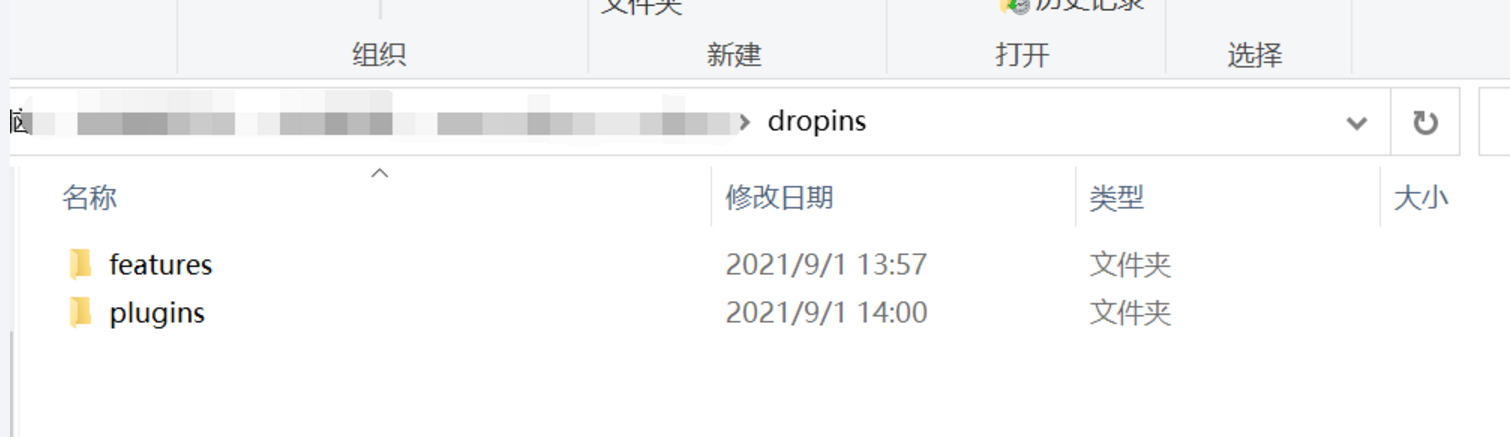
第三种方法:这种方法与第一种方法类似,需要将eclipse的plugins和features文件夹复制一份放在dropins文件夹下,不过要注意的是只要一层文件夹,切记不要隔着,完成所有操作之后重启eclipse。
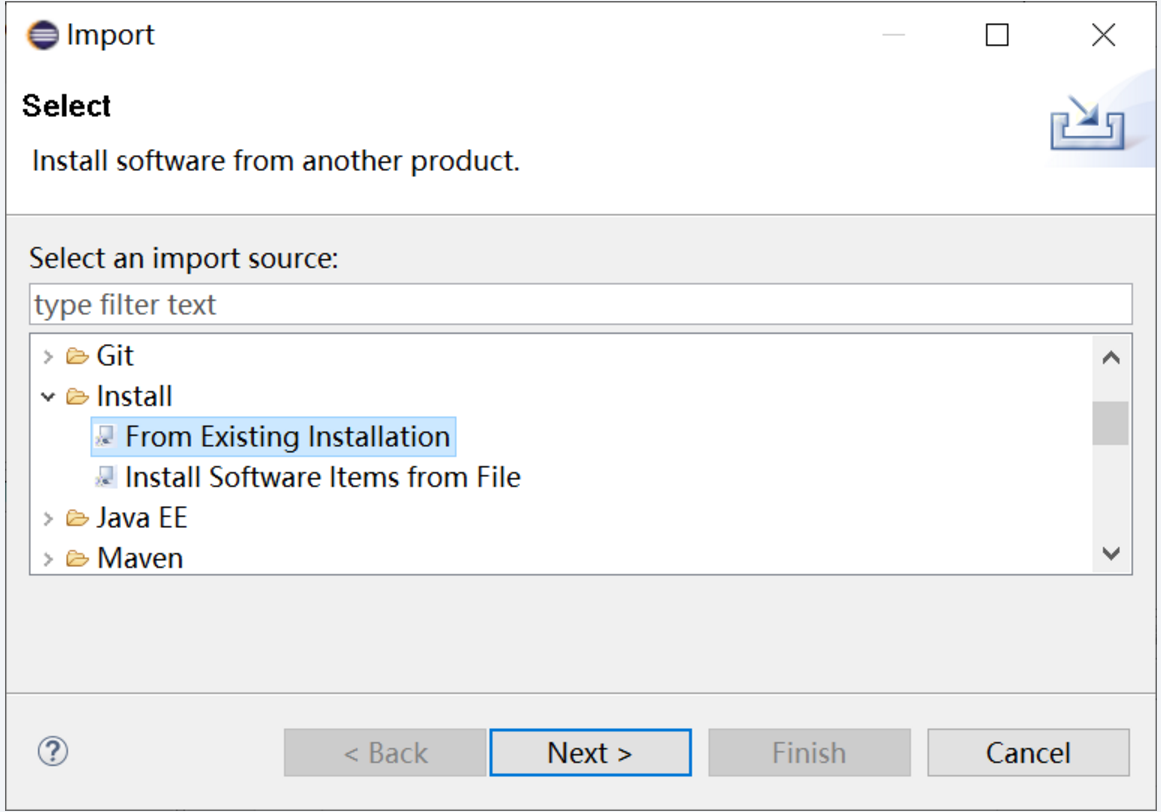
第四种方法:这是一个比较冷门的方法,首先需要打开file,然后找到import,并且点击import,之后在打开的弹窗中找到install,然后找到From existing Installation,最后需要点击next。
-
JAVA15中面世的新功能发布在 极客生涯
JEP 339 爱德华曲线算法(EdDSA):Java 15 中增加了一个新的密码学算法,爱德华曲线算法(EdDSA)签名算法。它是由 Schnorr 算法发展而来,在 RFC8032 中被定义实现。
EdD SA 是一种新型的椭圆曲线签名方案,与现有的签名方案相比有许多优点。JDK.这个 JEP 的主要目标是在 RFC 8032 中标准化的实现这个方案。这个新的签名方案并不能取代 EC DSA 。
其他执行目标:在相同的安全强度下,开发一个独立于平台的 EdDS A 实现,其性能优于现有的 EC DSA 实现(使用本机 C 代码)。例如,使用 curve 25519 在~ 126 位的安全性的 EdDS A 应该和使用曲线 secp 256r1 在~ 128 位安全的 EC DSA 一样快。
假设平台在恒定时间内执行 64 位整数加法/乘法,则确保计时与机密无关。此外,执行将不涉及机密。这些属性对于防止侧信道攻击非常有价值。
JEP 360:Sealed Classes(密封类)预览:我们都知道,在 Java 中如果想让一个类不能被继承和修改,这时我们应该使用 final 关键字对类进行修饰。不过这种要么可以继承,要么不能继承的机制不够灵活,有些时候我们可能想让某个类可以被某些类型继承,但是又不能随意继承,是做不到的。Java 15 尝试解决这个问题,引入了 sealed 类,被 sealed 修饰的类可以指定子类。这样这个类就只能被指定的类继承。
而且 sealed 修饰的类的机制具有传递性,它的子类必须使用指定的关键字进行修饰,且只能是 final 、sealed 、non-sealed 三者之一。
JEP 371:Hidden Classes(隐藏类):这个特性让开发者可以引入一个无法被其他地方发现使用,且类的生命周期有限的类。这对运行时动态生成类的使用方式十分有利,可以减少内存占用。
JEP 374:禁用和废弃偏向锁(Biased Locking):在之前,JVM 在处理同步操作,如使用 synchronized 同步时,有一套锁的升级机制,其中有一个锁机制就是偏向锁。然而通过目前的 Java 开发环境来看,使用这些被 synchronized 同步的类的机会并不多,如开发者更喜欢使用 HashMap 或者 ArrayList 而非 HashTable 和 Vector。
即使换个角度,当初使用偏向锁是为了提高性能,如今看来性能提升的程度和使用次数都不太有用。而偏向锁的引入增加了 JVM 的复杂性。所以现在偏向锁被默认禁用,在不久的将来将会彻底删除,对于 Java 15,我们仍然可以使用-XX:+UseBiasedLocking 启用偏向锁定,但它会提示 这是一个已弃用的 API。

-
go语言snowflake雪花算法发布在 开源推荐
依据Go 语言实现的 Snowflake 算法,能够为分布式系统生成唯一ID,单机测试1秒可生成20万ID。
Snowflake雪花算法产生的背景是为了解决twitter高并发环境下对唯一ID生成的需求,并且得益于twitter内部牛逼的技术,实际在业务中,会需要使用一些唯一的ID,用来记录我们某个数据的标识。
最常用的记录方式无非以下几种:UUID方式、数据库自身自增主键、Redis的Incr命令等方法来获取一个唯一的值。
Snowflake雪花算法的原始版本是scala版,最开始的存在是用于生成分布式ID,以纯数字的方式,并且按照时间顺序,应用在实际中还可以生成订单编号等。
数据库自增ID:劣势在于对于数据敏感场景不宜使用,且不适合于分布式场景。 GUID:使用时会采用无意义字符串,且数据量增大时造成访问过慢,最大的缺陷在于不宜排序。
Snowflake 结构是一个 64bit 的 int64 类型的数据。在应用到实际情况时可以根据自己的业务情况进行调整。
Snowflake雪花算法的实现步骤是非常简单的,首先需要获取当前的毫秒时间戳;并且用当前的毫秒时间戳和上次保存的时间戳进行比较;此时会出现两种情况,如果和上次保存的时间戳相等,那么对序列号 sequence 加一;如果不相等,那么直接设置 sequence 为 0 即可;然后通过或运算拼接雪花算法需要返回的 int64 返回值。
项目地址:
https://gitee.com/GuaikOrg/go-snowflake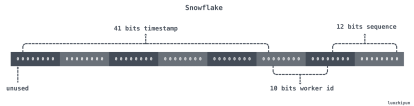
-
golang开发目录结构发布在 开源推荐
go项目本身也是用go语言实现的,其中包括它的编译器,如果想要研究go源代码的可以看此项目录。
main函数文件(比如 /cmd/myapp.go)目录,在这个目录下面,所有的文件在编译之后都能够生成一个可执行的文件。但是要注意不能够把很多的代码放到这个目录下面,这个目录里面的代码要尽可能简单。
/internal:应用程序的封装的代码,分为两类,其中某个应用私有的代码放到 /internal/myapp/ 目录下,而多个应用共有的公共的代码,则放在 /internal/common 之类的目录下面。
/pkg:一些通用的代码、能够被其他项目所使用的代码,则放到这个目录下面;/vendor:项目所依赖的其他第三方库、代码,则使用 glide 工具来管理依赖。
/api:协议文件,Swagger/thrift/protobuf 等;/web:web服务所需要的静态文件;/configs:配置文件;/init:服务启停脚本;
/scripts:其他一些脚本,编译、安装、测试、分析等;/build:持续集成目录;云 (AMI), 容器 (Docker), 操作系统 (deb, rpm, pkg)等的包配置和脚本放到 /build/package/ 目录。
/deployments:部署相关的配置文件和模板;/test:其他测试目录,功能测试,性能测试等;/docs:是一类设计文档;/tools:是常用的工具和脚本,它可以引用internal或者pkg里面的库来使用;/examples:应用程序或者公共库使用的一些例子。

项目地址:
https://github.com/golang/go