基于Lucene的全文检索实践
-
数据可以分为结构化数据和非结构化数据,对数据查询时,结构化数据可以通过SQL语句等方式查询,而非结构化数据(如txt,word等)无法用此方式查询。
我们利用将非结构化数据转化为非结构化数据(即先将文件中单词按空格拆分,把单词创建一个索引,然后查询索引,根据单词和文档的关系找到文档列表,即全文检索),进行快速查询。
在全文检索的流程中:绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:确定原始内容即要搜索的内容→采集文档→创建文档→分析文档→索引文档。 红色表示搜索过程,从索引库中搜索内容,搜索过程包括:用户通过搜索界面→创建查询→执行搜索,从索引库搜索→渲染搜索结果。
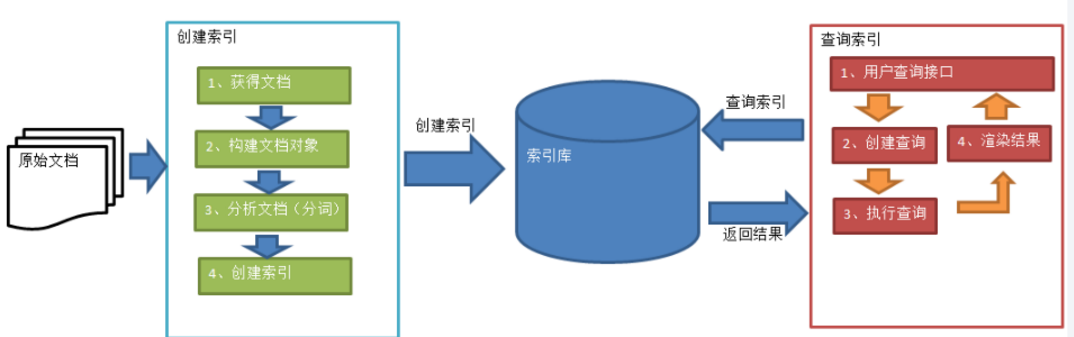
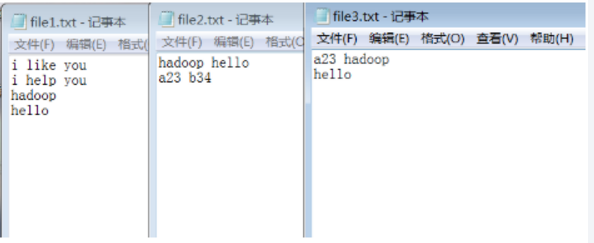
倒排索引即为全文检索的核心的部分,所谓倒排索引,简单地就是,根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。这就像百度里的搜索,你输入一个关键字,那么百度引擎就迅速的在它的服务器里找到有该关键字的文件,并根据频率和其他的一些策略等来给你返回结果。这个过程中,倒排索引就起到很关键的作用。

西南地区IT社群(QQ)
- 云南
- 【昆明网页设计交流吧】243627302
- 【昆明nodejs交流吧】 243626749
- 【VUE】838405306
- 【云南程序员总群】343606807
- 【昆明UI设计】104031254
- 【云南软件外包】15547313
- 贵州
- 【PHP/java源码/站长交流群】55692114
- 四川
- 【成都Java/JavaWeb交流】86669225
- 【vaScript+PHP+MySql】116270060
- 【UI设计/设计交流学习群】135794928
- 重庆
- 【诺基亚 JAVA游戏博物馆】 559479780
- 【PHP,Java,Python,C++接单】 442103442
- 西藏