用栈实现算术表达式的运算,需要两个栈:一个用于保存操作数,一个用于保存操作码(运算符)。
当一直扫描到第一个减号(-)时,两个栈都是在进行入栈操作。
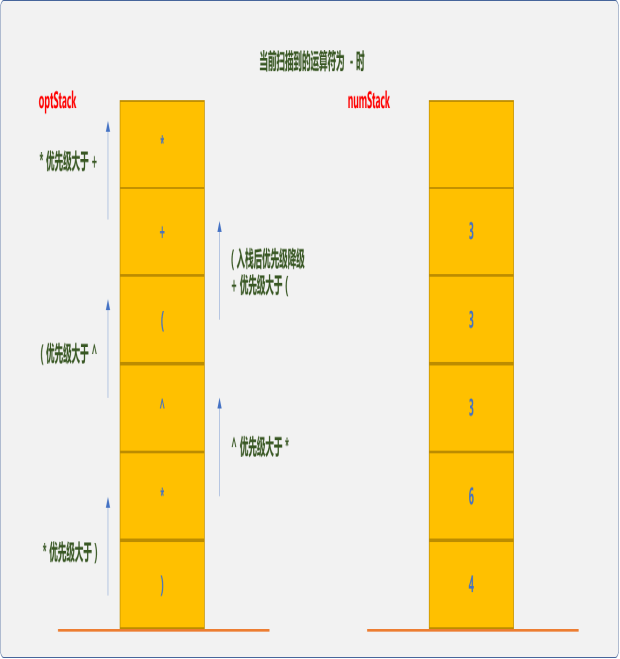
因 -(减法)运算符优先级低于optStack栈顶的运算符。这时从optStack栈中弹出,再从numStack中弹出3和3 两个操作数,进行乘法运算33=9,并把结果压入numStack栈中。
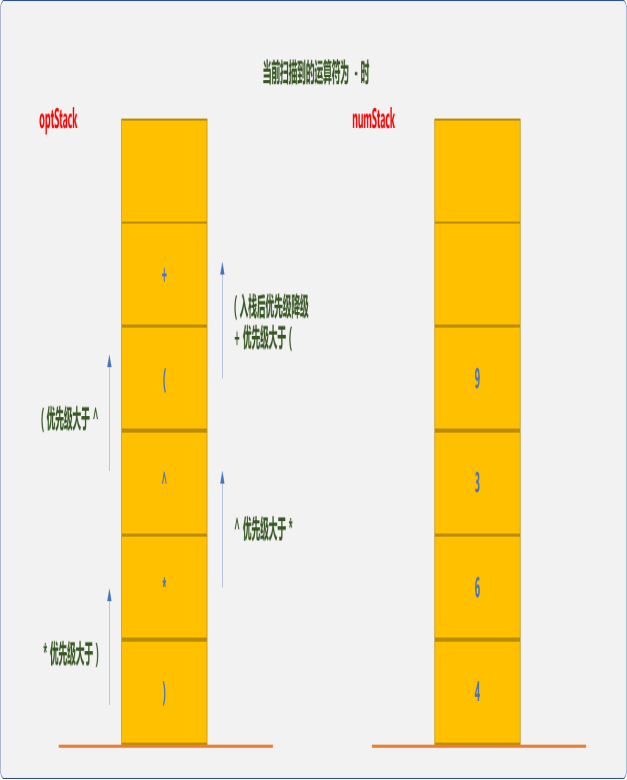
计算完成后,因-(减法)和+(加法)的优先级相同,栈内优先。此时,把+从optStack栈中弹出,并从numStack中相继弹出9和3,计算3+9=12,并把结果压入numStack栈中。
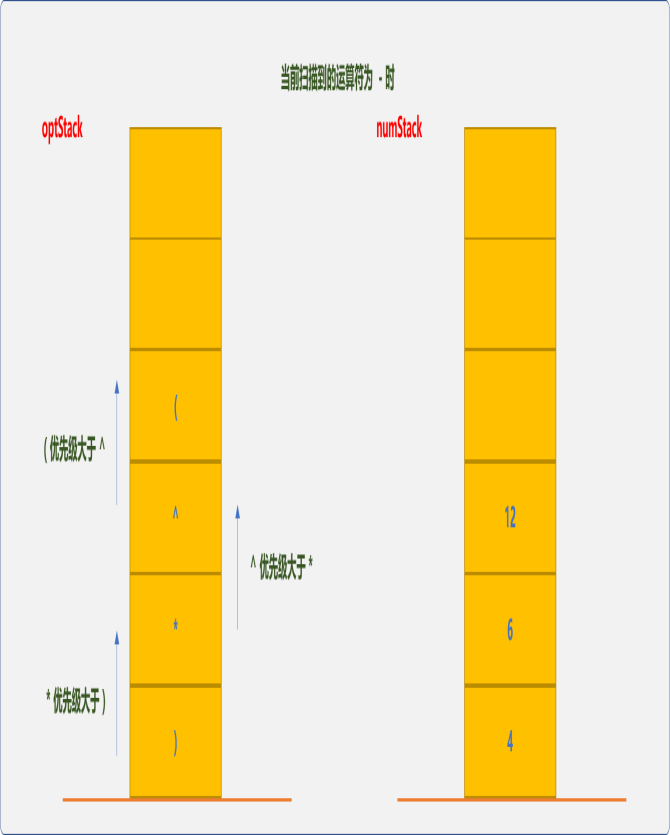
因-(减法)优先级大于栈中(的优先级,-入栈。
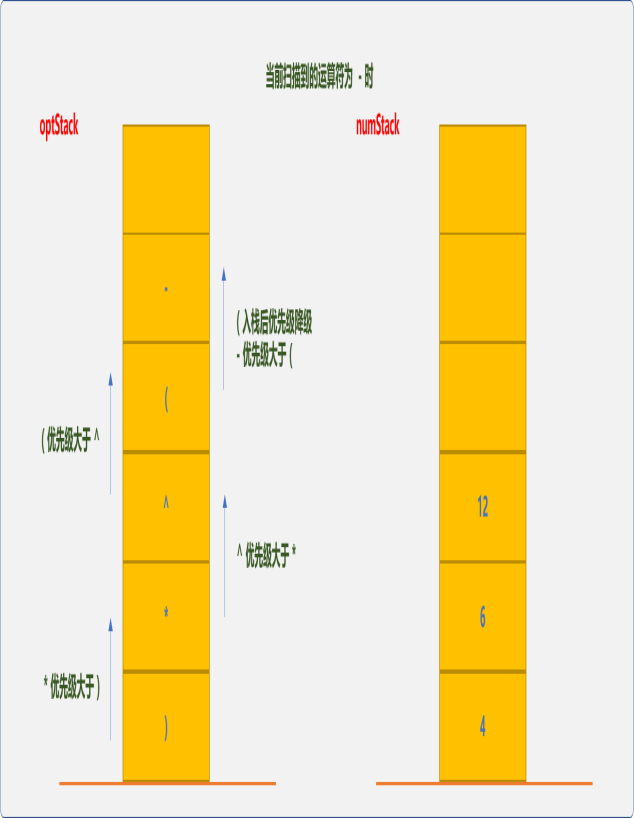
继续扫描,直到遇到右括号。
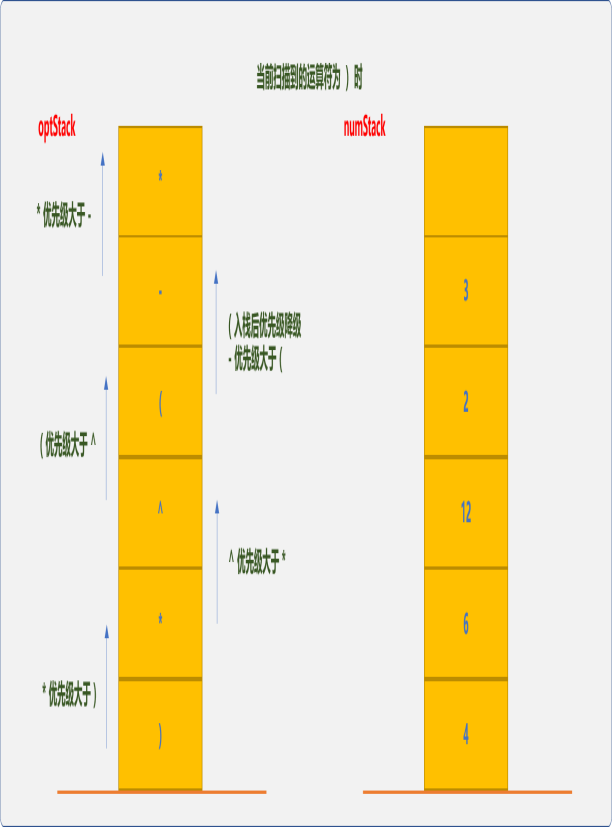
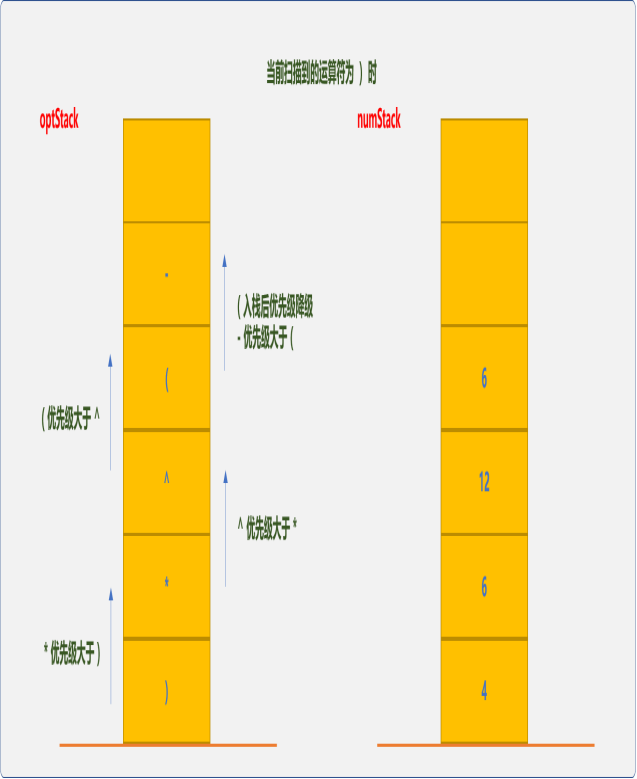
因右括号的优先级最低,或者说表示子表达式到此结束,此时从optStack栈中依次弹出运算符,从numStack中相应弹出 2 个操作数,计算后把结果压入numStack中,直到在optStack栈中遇到左括号。
弹出对3和2进行计算。并把结果6压入numStack中。
弹出-运算符,并对numStack栈中的12和6进行计算。
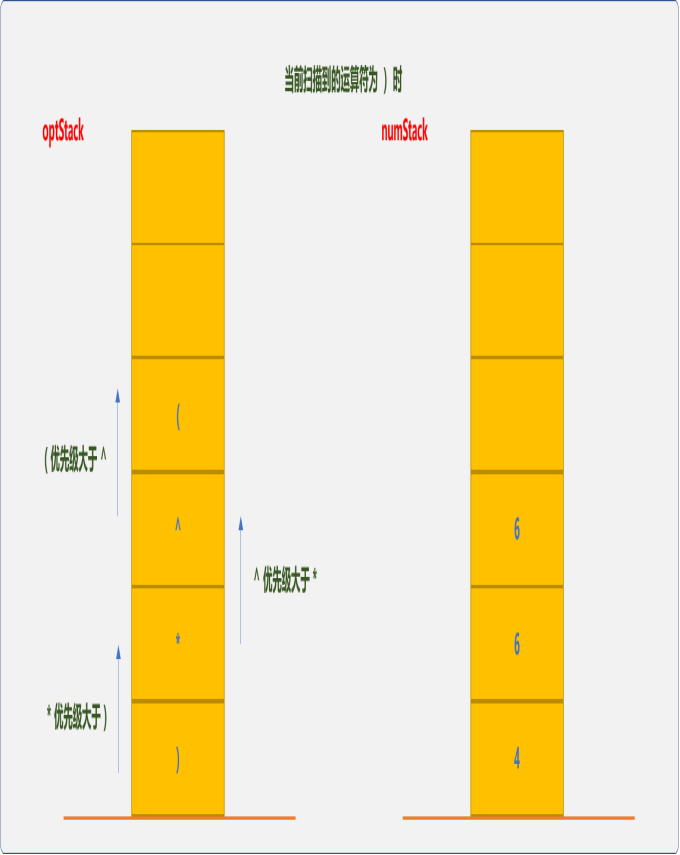
(出栈,表示由括号表示的子表达式计算结束。继续扫描到第二个-
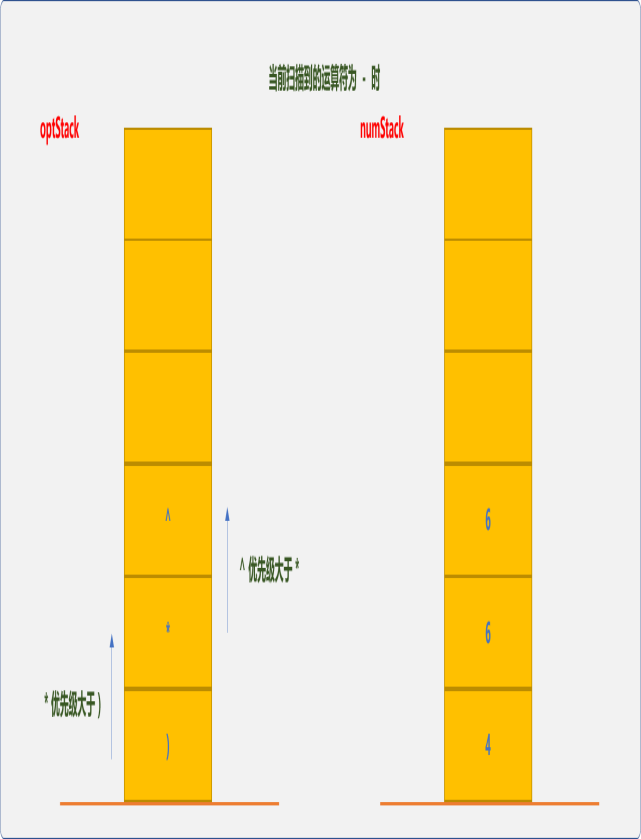
因-优先级小于^,先做6^6=46656乘方运算 。
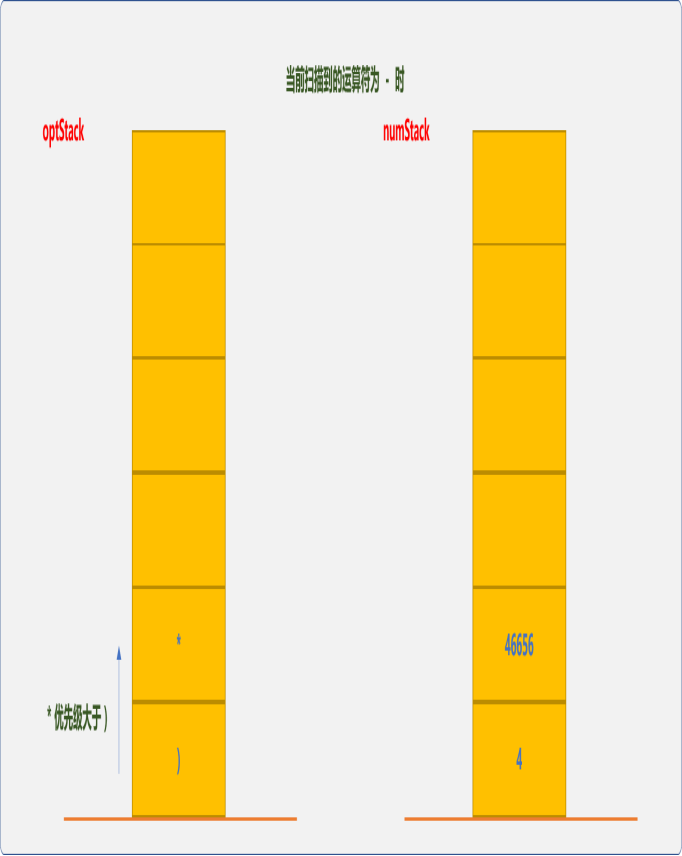
-优先级小于*,继续做乘法运算,46656*4=186624。

-入栈,最后一个数字 8入栈。
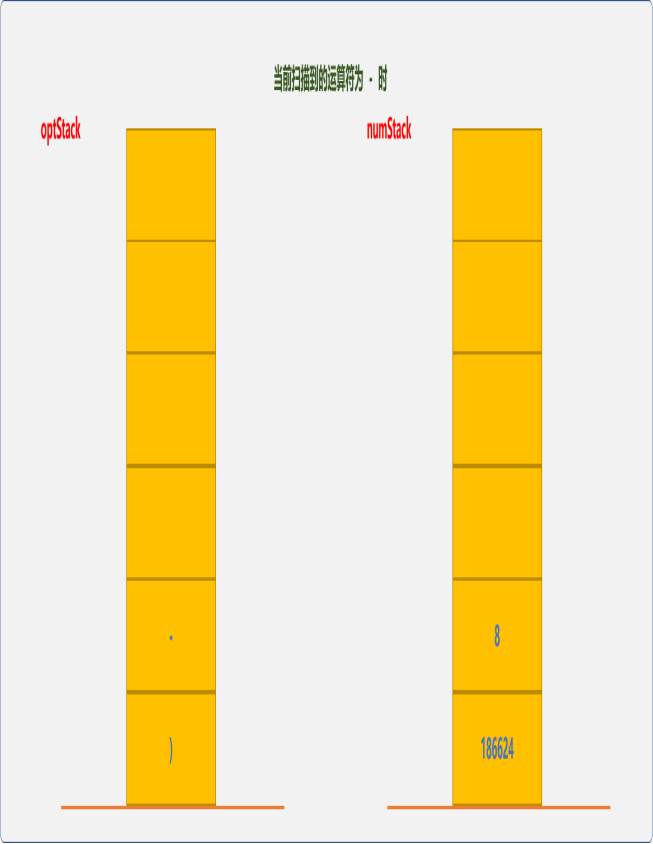
因整个表达式结束,弹出-,做最后的减法运算186624-8=186616。整个表达式结束,numStack栈顶的结果为表达式的最后结果。

q464824151 发布的帖子
-
用栈演示表达式4*6^(3+3*3-2*3)-8 的求值过程发布在 技术答疑
-
冗余备份的重要性发布在 技术答疑
如今社会,网络是各个产业的新的血脉,网络的稳定性至关重要,一旦网络出现故障,导致断网、延迟丢包等很可能会导致生产作业停滞,造成较经济损失,为此冗余备份至关重要,从链路和节点我总结出了几种冗余备份方式。
二层设备使用到STP类的协议、链路聚合。三层设备使用动态路由、VRRP、VGMP(华为防火墙专用)。-
链路备份方法:设备与设备之间的链路部分,是非常容易出现故障的,比如光纤被施工队挖断了、光收发损坏、水晶头老化等等问题,都会导致网络断路,从而“收获投诉”。可以可以通过一些手段去解决。
-
有线链路备份:所以在一般的网络设计中,会敷设多条网络的链路,比如比较重要的汇聚点之间设备敷设两条光纤,在某条光纤出现链路故障时候可以进行手动的切换(手动接线)。当然可以通过设备,如果是二层交换机设备,可以配合链路聚合实现负载均衡和带宽叠加。
可以分为物理层+数据链路层两种情况。
备份线:交换机/路由器<->终端设备 设置多条链路,某条链路故障时候可以手动更换到新的链路
备份线后,链路聚合:交换机<->交换机 设置多条链路,链路互相连接到同一个设备,设置链路聚合绑定(注意开启STP类的协议)
-
-
讲讲 trylock、lock方法发布在 技术答疑
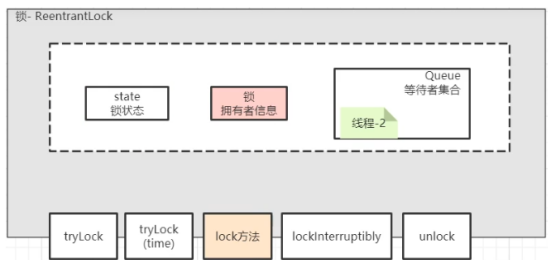
lock 锁设计上的核心成员:锁状态、锁拥有者、等待队列;源码方面:在 ReentrantLock 中 使用了关键成员是同步器AQS(源码中的Sync)
-
trylock方法:获取锁/是否锁成功;锁的状态,0 代表未占用锁,大于0 则代表占用锁的次数。首先当前线程以CAS的方式,尝试将锁的状态从0修改成1,就是尝试获取锁。
获取到了就把当前线程设置给AQS的属性exclusiveOwnerThread,也就是指明当前锁的拥有者是当前线程。 -
lock方法:加锁。非公平锁模式,首先当前线程以CAS的方式,尝试将锁的状态从0修改成1,就是尝试获取锁。获取到了就把当前线程设置给AQS的属性exclusiveOwnerThread,也就是指明当前锁的拥有者是当前线程。
当前锁已经被占用,线程会进入等待队列,不断地抢锁,抢到锁直接从等待队列弹出,否则判断线程的状态是否需要挂起(阻塞),这里循环抢锁,不断调用了尝试获取锁的方法,也利用了CAS思想。
-
-
Spring Cloud 与 K8S 对比发布在 技术答疑
两个平台 Spring Cloud 和 Kubernetes 非常不同并且它们之间没有直接的相同特征。
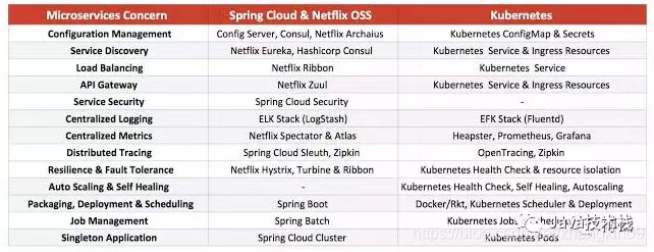
两种架构处理了不同范围的MSA障碍,并且它们从根本上用了不同的方法。Spring Cloud方法是试图解决在JVM中每个MSA挑战,然而Kubernetes方法是试图让问题消失,为开发者在平台层解决。Spring Cloud在JVM中非常强大,Kubernetes管理那些JVM很强大。同样的,它就像一个自然发展,结合两种工具并且从两个项目中最好的部分受益。
可以看到,里面差不多一半关注点是和运维相关的。这么看来,似乎拿spring cloud和kubernetes比较有点不公平,spring cloud只是一个开发框架,对于应用如何部署和调度是无能为力的,而kubernetes是一个运维平台。
也许用spring cloud+cloud foundry去和kubernetes比较才更加合理,但需要注意的是,即使加入了cloud foundry的paas能力,spring cloud仍然是“侵入式”的且语言相关,而kubernetes是“非侵入式”的且语言无关。
-
MySQL数据库深分页查询优化发布在 技术答疑
MySQL 同步 ES 流程如下:
通过定时任务的形式触发同步,比如间隔半天或一天的时间频率
同步的形式为增量同步,根据更新时间的机制,比如第一次同步查询 >= 1970-01-01 00:00:00.0
记录最大的更新时间进行存储,下次更新同步以此为条件
以分页的形式获取数据,当前页数量加一,循环到最后一页
在这里问题也就出现了,MySQL 查询分页 OFFSET 越深入,性能越差,初步估计线上 MCS_PROD 表中记录在 1000w 左右
如果按照每页 10 条,OFFSET 值会拖垮查询性能,进而形成一个 "性能深渊"
同步类代码针对此问题有两种优化方式:
采用游标、流式方案进行优化
优化深分页性能

MySQL 耗费了 大量随机 I/O 在回表查询聚簇索引的数据上,而这 100000 次随机 I/O 查询数据不会出现在结果集中
如果系统并发量稍微高一点,每次查询扫描超过 100000 行,性能肯定堪忧,另外 LIMIT 分页 OFFSET 越深,性能越差 -
需要拥有什么才能达到丝滑的消息治理发布在 技术答疑
-
强大的监控体系:服务端监控。MQ本身就是一个程序,那么这个程序本身的健康状况我们需要关注,假设我们的MQ是Java开发的,那么JVM指标也需要监控。同时发消息的耗时啊等等都需要监控。
-
服务器层面监控:无论你的MQ是部署在物理机上还是容器上,MQ都依赖它。所以对于服务器层面的监控也是必不可少。像CPU, 内存,磁盘IO,网络等等。
-
业务层面监控:消息堆积对在线业务场景有很大的影响,必须具备实时监控的能力。当有消息堆积时及时通过 告警机制通知业务团队进行处理。
-
QPS飙升:当整个集群或者某个Topic级别的消息发送量在1分钟之内极度飙升,那么需要及时关注。因为很有可能会超过MQ本身的承受范围,同时消费方也会产生堆积问题。
-
死信消息:当消费者消费某条消息一直失败的时候,已经超过了最大重试次数,这条消息会进入死信队列。这块也是需要及时监控,因为一旦有死信消息,也就是意味着你的消费逻辑存在问题,需要及时修复。
-
消费失败率:当消费方消息消息,频繁失败的时候,也需要有对应的监控告警。这个其实在MQ的client包里面就可以进行数据的埋点上报。
-
强大的运维体系:集群自动化部署:当规模到达一定的时候,一定要具备高度自动化的能力。就像云产品一样,今天业务团队需要一个新的集群,直接走工单审批,等审批通过后集群自动创建好。
-
集群弹性扩容:有了自动化部署后,弹性扩容也是水到渠成的事情。当集群的QPS超过了本身能够承载的量,必然会进行限流,但是一旦限流,也就意味着业务功能有损。所以具备弹性扩容的能力非常重要,最好是自动化的弹性扩容。
资源隔离也十分的非常重要,我们用MQ也是不同的业务场景,不同的场景对稳定性的要求也不一样。比如在线交易场景的稳定性肯定要高于一些后台操作类的场景。
比如订单会将订单的生命周期通过消息的形式发送出去,各个业务域按需进行订阅。如果订单的集群跟其他业务共用一套,当其他业务出现某些问题的时候,那么就会影响订单的消息,所以要针对业务场景进行资源的隔离。
-
强大的治理后台:Topic&Group管理:Topic和Group的管理是最基本的功能,每个迭代都会有新增的Topic和Group,所以能够通过后台快速创建Topic和Group至关重要。
同时也能查看Topic中的消息,Group的在线情况,消费情况等等信息。 -
账号权限体系:当公司组织规模大了后,严格的账号权限体系必不可少。无论是Topic和Group的创建,还是消息查询的权限,MQ吞吐量的数据等等,都需要严格控制权限,不能随意公开。其次,对于操作类的申请,要结合审批流进行多层审批,提高安全系数。
-
消息轨迹:消息轨迹在实际排查问题的时候非常有用,通过消息轨迹,我们可以查看某条消息到底有没有被消费?是谁消费了这条消息?消费耗时了多久?这个功能在很多MQ中都是支持的。
-
消费位重置:消费位重置指的是通过后台,我们可以将消费点进行倒退到某一个时间点,然后重新将这个时间点之后的消息进行投递,让消费者再消费一次的操作。一般情况下这个功能是用不到的,但是某些场景还是有可能用到。
其实最常用的就是某一条消息进行重新投递,比如我们在测试环境出了一个什么问题,然后想验证下,这个时候可以去后台将这个消息重新投递一次,然后再观察下日志,去排查问题。

-
-
模块依赖和启动模块发布在 技术答疑
一个业务应用通常由多个模块组成,ABP 框架允许您声明模块之间的依赖关系。一个应用必须要有一个启动模块。启动模块可以依赖于其他模块,其他模块可以再依赖于其他模块,以此类推。
下图是一个简单的模块依赖关系图:
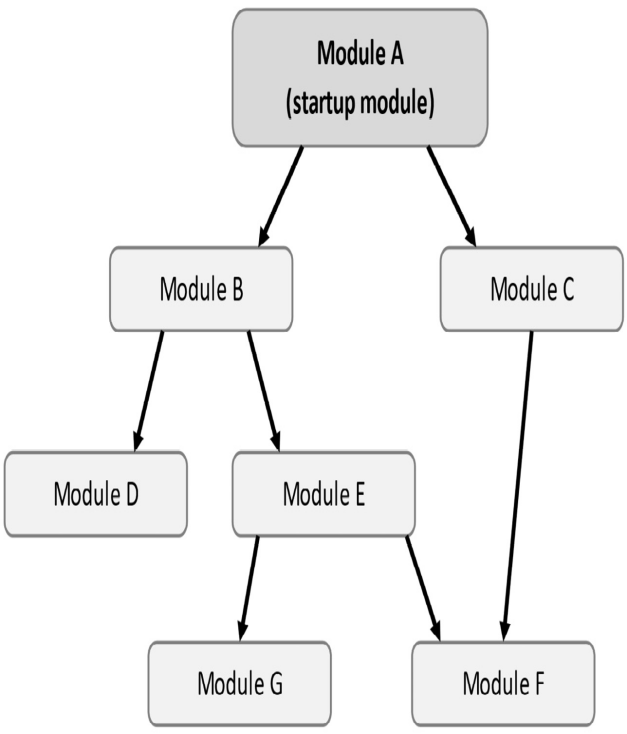
如果所示,如果模块 A 依赖于模块 B,则模块 B 总是在模块 A 之前初始化。这允许模块 A 使用、设置、更改或覆盖模块 B 定义的配置和服务。对于示例图,模块初始化的顺序应该是:G、F、E、D、B、C、A。模块生命周期:AbpModule中定义的生命周期方法,除了上面看到的ConfigureServices和OnApplicationInitialization,下面罗列其他生命周期相关方法:
- PreConfigureServices: 这个方法在ConfigureServices方法之前被调用。它允许您配置服务之前执行的代码。
- ConfigureServices:这是配置模块和注册服务的主要方法。
- PostConfigureServices: 该方法在ConfigureServices之后调用(包括依赖于您模块的模块),这里可以配置服务后执行的代码。
- OnPreApplicationInitialization: 这个方法在OnApplicationInitialization之前被调用。在这个阶段,您可以从依赖注入中解析服务,因为服务已经被初始化。
- OnApplicationInitalization:此方法用来配置 ASP.NET Core 请求管道并初始化您的服务。
- OnApplicationInitialization: 这个方法在初始化阶段后被调用。
- OnApplicationShutdown:您可以根据需要自己实现模块的关闭逻辑。
带Pre…和Post…前缀的方法与原始方法具有相同的目的。它们提供了一种在模块之前或之后执行的一些配置/初始化代码,一般情况下我们很少使用到。
-
一起创建并配置一个发布在 技术答疑
创建 Filter 需要实现 javax.servlet.Filter 接口,或者继承实现了 Filter 接口的父类。Filter 接口中定义了三个方法:
init方法:用于Web 程序启动时被调用,用于初始化 Filter。
doFilter:在客户端的请求到达时被调用,doFilter 方法中定义了 Filter 的主要处理逻辑,同时该方法还负责将请求传递给下一个 Filter 或 Servlet。
destroy:在 Web 程序关闭时被调用,用于销毁一些资源。

init 方法的 filterConfig 参数封装了当前 Filter 的配置信息,在 Filter 初始化时,我们将 Filter 的名称打印在控制台。doFilter方法定义了 Filter 拦截到用户请求后的处理逻辑,filterChain.doFilter(servletRequest, servletResponse);指的是将请求传递给一下个 Filter 或 Servlet,如果不添加该语句,那么请求就不会向后传递,自然也不会被处理。在该语句之后,可以添加对响应的处理逻辑(如果要修改响应的 Header,可直接在该语句之前修改;如果要修改响应的内容,则需要在该语句之后,且需要自定义一个 response)。
destroy 方法中,我们输出 "Filter 被回收" 的提示信息。在下面的代码中,setFilter 方法用于设置 Filter 的类型;addUrlPatterns 方法用于设置拦截的规则;setName 方法用于设置 Filter 的名称;setOrder 方法用于设置 Filter 的优先级,数字越小优先级越高。

-
浅聊一下过滤器和拦截器发布在 技术答疑
过滤器 Filter 是 Sun 公司在 Servlet 2.3 规范中添加的新功能,其作用是对客户端发送给 Servlet 的请求以及对 Servlet 返回给客户端的响应做一些定制化的处理,例如校验请求的参数、设置请求/响应的 Header、修改请求/响应的内容等。
Filter 引入了过滤链(Filter Chain)的概念,一个 Web 应用可以部署多个 Filter,这些 Filter 会组成一种链式结构,客户端的请求在到达 Servlet 之前会一直在这个链上传递,不同的 Filter 负责对请求/响应做不同的处理。 Filter 的处理流程如下图所示:
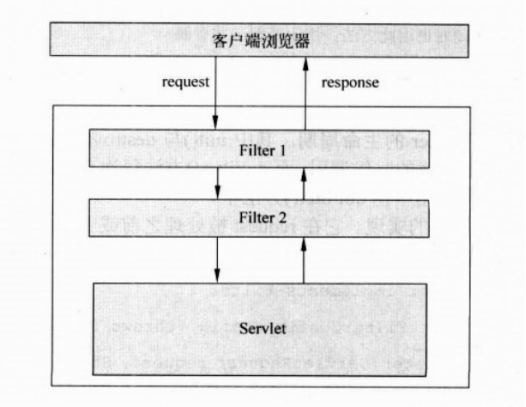
拦截器 Interceptor 是 Spring MVC 中的高级组件之一,其作用是拦截用户的请求,并在请求处理前后做一些自定义的处理,如校验权限、记录日志等。这一点和 Filter 非常相似,但不同的是,Filter 在请求到达 Servlet 之前对请求进行拦截,而 Interceptor 则是在请求到达 Controller 之前对请求进行拦截,响应也同理。
与 Filter 一样,Interceptor 也是 AOP 编程思想的体现,且 Interceptor 也具备链式结构,我们在项目中可以配置多个 Interceptor,当请求到达时,每个 Interceptor 根据其声明的顺序依次执行。
postHandle 方法和 afterCompletion 方法执行的前提条件是 preHandle 方法的返回值为 true。如果 Controller 抛出异常,那么 postHandle 方法将不会执行,afterCompletion 方法则一定执行。

-
哈希函数发布在 极客生涯
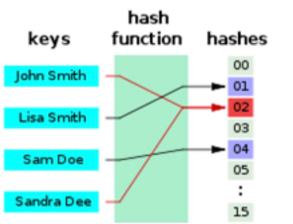
哈希函数,或者叫散列函数,是一种从任何一种数据中创建一个数字指纹(摘要)的方法,散列函数把数据压缩压缩(或者放大)成一个长度固定的摘要。
哈希函数的输入空间(文本或者二进制数据)是无限大,但是输出空间(一个固定长度的摘要)却是有限的。将「无限」映射到「有限」,不可避免的会有概率不同的输入得到相同的输出,这种情况我们称为碰撞(collision)。
一个简单的哈希函数是直接对输入数据/文本的字节求和。它会导致大量的碰撞,例如 hello 和 ehllo 将具有相同的哈希值。
更好的哈希函数可以使用这样的方案:它将第一个字节作为状态,然后转换状态(例如,将它乘以像 31 这样的素数),然后将下一个字节添加到状态,然后再次转换状态并添加下一个字节等。这样的操作可以显着降低碰撞概率并产生更均匀的分布。
一个好的「加密哈希函数」必须满足抗碰撞(collision-resistant)和不可逆(irreversible)这两个条件。
抗碰撞是指通过统计学方法(彩虹表)很难或几乎不可能猜出哈希值对应的原始数据,而不可逆则是说攻击者很难或几乎不可能从算法层面通过哈希值逆向演算出原始数据。一个理想的加密哈希函数,应当具有如下属性:- 快速:计算速度要足够快;
- 确定性:对同样的输入,应该总是产生同样的输出;
- 难以分析:对输入的任何微小改动,都应该使输出完全发生变化;
- 不可逆:从其哈希值逆向演算出输入值应该是不可行的。这意味着没有比暴力破解更好的破解方法。
- 无碰撞:找到具有相同哈希值的两条不同消息应该非常困难(或几乎不可能)。
现代加密哈希函数(如 SHA2 和 SHA3)都具有上述几个属性,并被广泛应用在多个领域,各种现代编程语言和平台的标准库中基本都包含这些常用的哈希函数。
-
CoLAKE的模型方法发布在 极客生涯
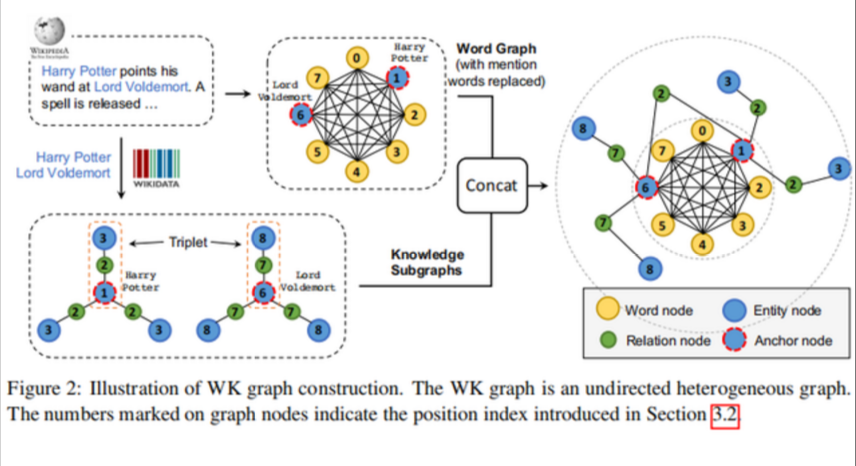
CoLAKE模型存在的目的是对结构化的、无标签的word-knowledge graphs的数据上对结合了上下文的语言和知识表征进行联合的、同步的预训练。其实现方法是先构造出输入句子对应的WK graphs,然后对模型结构和训练目标稍作改动。具体实现如下:
- 构造一个WK graphs:先对输入的句子中的mention进行识别,然后通过一个entity linker的功能,找到其在特定知识图谱中对应的entity。Mention结点被替换为相应的entity,这个操作被称作为anchor nodes。
以这个anchor node为中心,还可以提取到多种三元组关系来形成子图,提取到的这些子图和句子中的词语,以及anchor node一起拼接起来形成WK graph。
实际上,对于每个anchor node,作者随机玄奇最多15个相邻关系和实体来构建WK graph,并且只考虑anchor node在三元组中是head的情况。
-
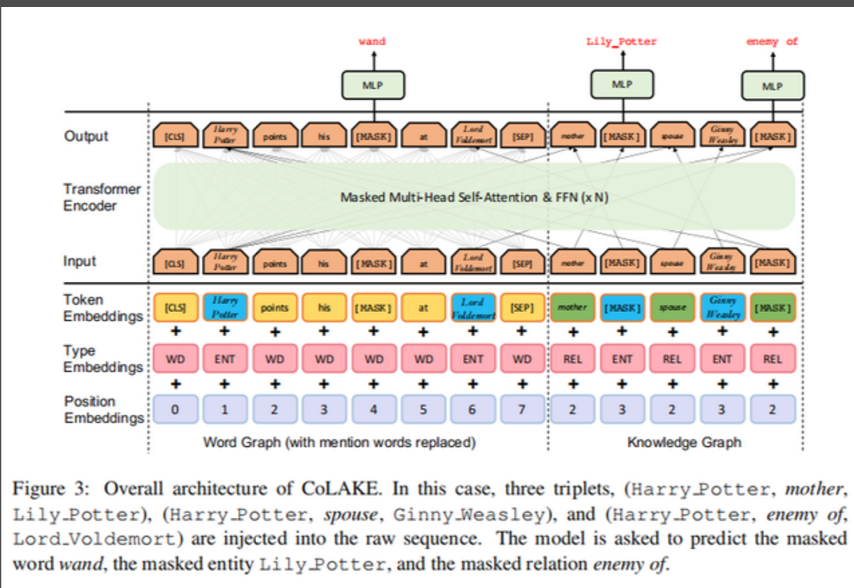
模型结构改动:接下来构建好的WK graph进入Transformer Encoder,CoLAKE对embedding层和encoder层都做了相应的改造。
-
Embedding Layer:输入的embedding是token embedding,type embedding和position embedding的加和。
其中,输入的token embedding需要构建word、relation和entity三种类型的查找表。
对于word embedding而言,采用Roberta一样的BPE的分词方法,将词语切割为字词用以维护大规模的词典。相应的,对每一个entity和relation就沿用一般的知识嵌套方法一样来获取对应的embedding。
然后输入中token embedding则是由word embedding,entity embedding, relation embedding拼接起来,这三者是同样维度的向量。因为WK graph会将原本的输入以token为单位进行重组,因此输入的token序列会看起来像是一段错乱的序列,因此需要对应修正其type input和position input。其中对于每个token,其同一对应的type会用来表征该token对应的node的类型,比如是word,entity或者是relation;对应的position也是根据WK graph赋予的。下图给出了一个具体的例子进行说明:
-
VLIW发布在 极客生涯
software和hardware之间总是存在tradeoff:要么是hardware结构复杂,software灵活。要么是hardware结构保持简洁清晰,software干一些脏活累活。VLIW就是属于后一种。
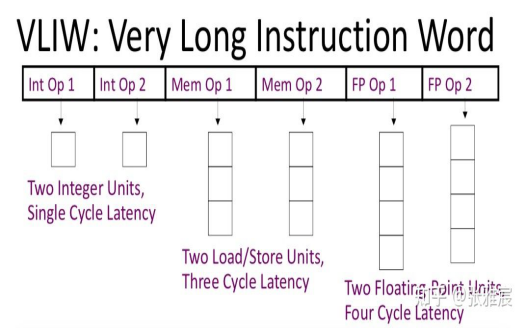
与Superscalar架构不同,VLIW将检查指令依赖关系的工作全部交给了编译器:编译器将没有依赖关系的指令打包成一个bundle,hardware不需要动态调度,只是负责取指、执行。VLIW创始人Josh Fisher于1983年发表的论文Very Long Instruction Word architectures and the ELI-512提出了VLIW的Trace Scheduling思想,优化代码中最经常执行的路径。不过当时很多科学家对这种方式持怀疑态度,也许从学术角度来看这种思想有点意思,但人们压根不相信,可以建造一台依靠software而不是hardware来提速的计算机。但是Josh Fisher一直相信VLIW架构远远超出了一个学术项目范畴,它有潜力改变所有的科学计算。
-
函数式编程发布在 极客生涯
函数式编程关心数据的映射,命令式编程关心解决问题的步骤
函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
只用"表达式",不用"语句":"表达式"(expression)是一个单纯的运算过程,总是有返回值;"语句"(statement)是执行某种操作,没有返回值。函数式编程要求,只使用表达式,不使用语句。也就是说,每一步都是单纯的运算,而且都有返回值。
没有"副作用"。所谓"副作用"(side effect),指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。
函数式编程强调没有"副作用",意味着函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。
函数式编程不依赖、也不会改变外界的状态,只要给定输入参数,返回的结果必定相同。因此,每一个函数都可以被看做独立单元,很有利于进行单元测试(unit testing)和除错(debugging),以及模块化组合。
高阶函数:假如你写了一大堆程序而不考虑什么类结构设计,然后发现有一部分代码重复了几次,于是你就会把这部分代码独立出来作为一个函数以便多次调用。
如果你发现这个函数里有一部分逻辑需要在不同的情况下实现不同的行为,那么你可以把这部分逻辑独立出来作为一个高阶函数。
-
大数据批处理和流处理标准Apache Beam发布在 极客生涯
Apache Beam 是 Apache 软件基金会越来越多的数据流项目中最新增添的成员,是 Google 在2016年2月份贡献给 Apache 基金会的孵化项目。
这个项目的名称表明了设计:结合了批处理Batch模式和数据流Stream处理模式。它基于一种统一模式,用于定义和执行数据并行处理管道pipeline,这些管理随带一套针对特定语言的SDK用于构建管道,以及针对特定运行时环境的Runner用于执行管道。
Apache Beam 的主要目标是统一批处理和流处理的编程范式,为无限、乱序、web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。Apache Beam项目重点在于数据处理的编程范式和接口定义,但是这并不涉及具体执行引擎的实现,Apache Beam希望基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上。
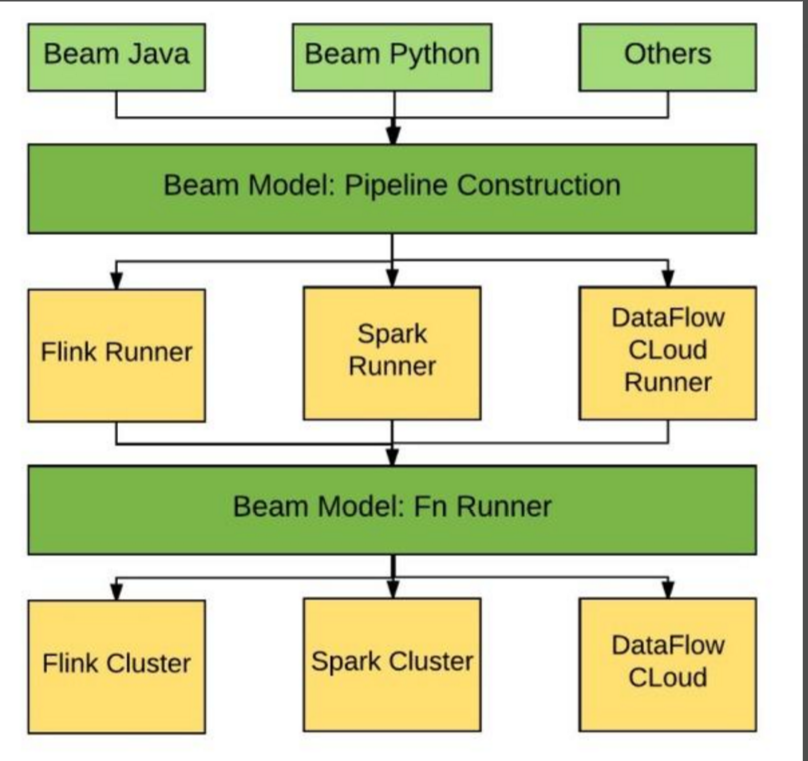
-
Fixture固件发布在 极客生涯
Fixture 翻译成中文即是固件的意思。它其实就是一些函数,会在执行测试方法/测试函数之前(或之后)加载运行它们,常见的如接口用例在请求接口前数据库的初始连接,和请求之后关闭数据库的操作。
- fixture的作用:完成setup和teardown操作,处理数据库、文件等资源的打开和关闭;完成大部分测试用例需要完成的通用操作,例如login、设置config参数、环境变量等;准备测试数据,将数据提前写入到数据库,或者通过params返回给test用例,等。
- fixture的优势:命名方式灵活,不局限于setup和teardown这几个命名;conftest.py 配置里可以实现数据共享,不需要import就能自动找到一些配置;scope="function",若多个用例都调用了fixture函数,则此fixture在每个用例开始前都执行一次。
scope="class",如果一个class的多个用例都调用了次fixture,则此fixture仅在第一次调用开始前执行一次,后续调用不执行。
scope="module" 在当前.py脚本里面所有用例开始前只执行一次。scope="session" 以实现多个.py跨文件使用一个session来完成多个用例。
-
数据结构发布在 极客生涯
数据结构(data structure)是带有结构特性的数据元素的集合,它研究的是数据的逻辑结构和数据的物理结构以及它们之间的相互关系,并对这种结构定义相适应的运算,设计出相应的算法,并确保经过这些运算以后所得到的新结构仍保持原来的结构类型。
简而言之,数据结构是相互之间存在一种或多种特定关系的数据元素的集合,即带“结构”的数据元素的集合。“结构”就是指数据元素之间存在的关系,分为逻辑结构和存储结构。数据的逻辑结构和物理结构是数据结构的两个密切相关的方面,同一逻辑结构可以对应不同的存储结构。算法的设计取决于数据的逻辑结构,而算法的实现依赖于指定的存储结构。
不知道大家觉得好不好理解,简单说来,计算机基本上就做两件事:存储数据和处理数据。数据结构,是老外总结出来的一套行之有效的数据存储方式,并围绕着这些存储方式设计出了一些高效的操作算法。借助数据结构,我们可以高效地管理多个数据,进而完成更复杂的功能。下图列举了一些常见的数据结构,后面会逐个进行讲解:
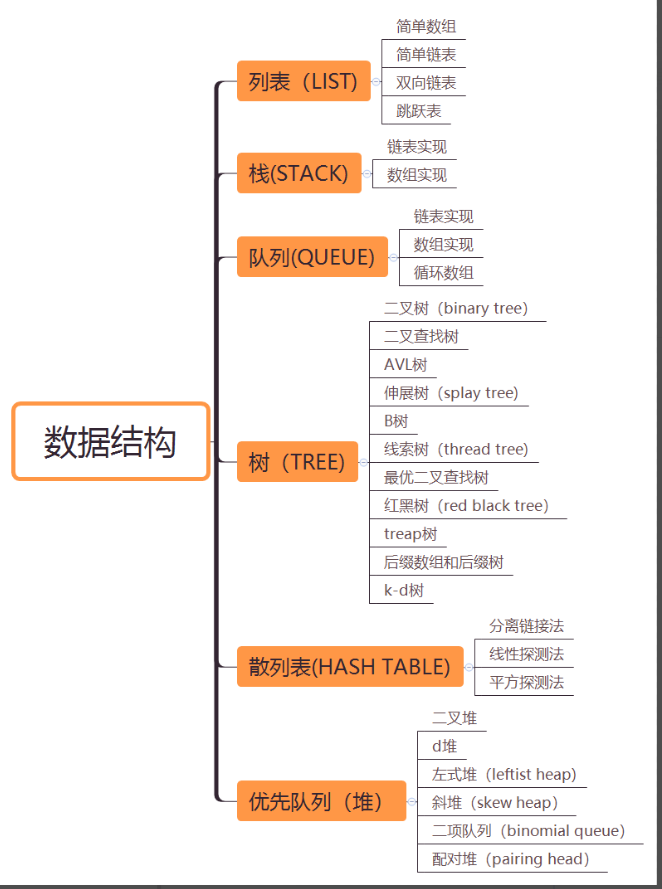
列表
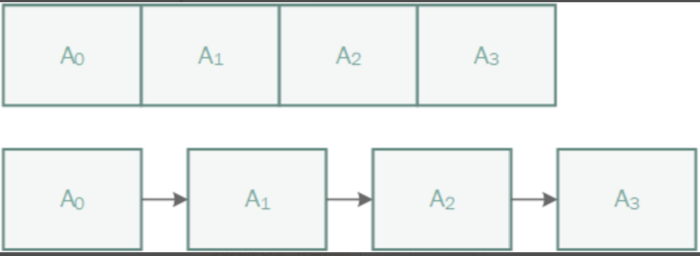
通常一系列数据A0,A1,A2,A3,...,AN-1 可以采用表来存储。表一般支持几种操作,寻找某元素所在位置,在表的某个位置插入和删除某元素,返回某个位置上的元素等。
栈:
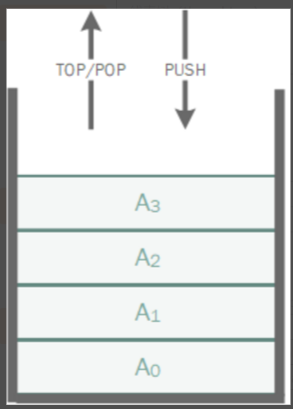
栈也叫LIFO(后进先出)表,元素的插入和访问、删除都只能从一个方向进行。通常支持入栈操作、出栈操作以及返回当前栈顶元素。 -
WebGPU缓冲映射发布在 极客生涯
什么是映射,简单的说,映射(Mapping)后的某块显存,就能被 CPU 访问。
三大图形 API(D3D12、Vulkan、Metal)的 Buffer(指显存)映射后,CPU 就能访问它了,此时注意,GPU 仍然可以访问这块显存。这就会导致一个问题:IO冲突,这就需要程序考量这个问题了。
WebGPU 禁止了这个行为,改用传递“所有权”来表示映射后的状态,颇具 Rust 的哲学。每一个时刻,CPU 和 GPU 是单边访问显存的,也就避免了竞争和冲突。
当 JavaScript 请求映射显存时,所有权并不是马上就能移交给 CPU 的,GPU 这个时候可能手头上还有别的处理显存的操作。所以,GPUBuffer 的映射方法是一个异步方法:
JavaScript 这端会在 rAF 中频繁地将大量数据传递给 GPUBuffer 映射出来的 ArrayBuffer,然后随着解映射、提交指令缓冲到队列,最后传递给 GPU.
上述最常见的例子莫过于传递每一帧所需的 VertexBuffer、UniformBuffer 以及计算通道所需的 StorageBuffer 等。
使用队列对象的 writeBuffer 方法写入缓冲对象是非常高效率的,但是与用来写入的映射后的一个 GPUBuffer 相比,writeBuffer 有一个额外的拷贝操作。推测会影响性能,虽然官方推荐的例子中有很多 writeBuffer 的操作,大多数是用于 UniformBuffer 的更新。
-
Relay pll和数据清理发布在 极客生涯
PLL使用闭环负反馈拓扑将接收信号的嵌入式时钟与标准的本地生成时钟相匹配。 PLL的原理和操作已经在技术文章,书籍和网站中得到了广泛的介绍,解释主要是口头的,直观的方法,一直到那些提供强大的数学分析的方法二和三。
虽然PLL多年来都是全模拟电路,但现在它们通常采用数字电路实现,例如,模拟VCO被数控振荡器取代功能。更高的频率下,模拟仍然是唯一可行的选择。
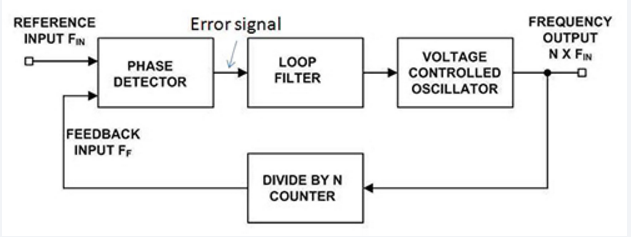
基本PLL是一种闭环,负反馈设计,可以比较本地生成的相位/频率与接收信号的相位/频率,并通过滤波后的误差信号调整VCO以跟踪输入信号。在所有PLL应用中,环路滤波器的细节对于证明所需的整体性能。当然,主滤波器参数是带宽,其次是诸如阻尼,滚降陡度,通带纹波和带外衰减等因素。
较窄的带宽将导致恢复的时钟输出抖动减少,这是一件好事。然而,这个相同的窄带宽意味着它将花费更长的时间来初始获取接收信号并在该信号经历频率变化时将其锁定。在无线链路中,这些频移通常是由于多径,失真,传播延迟问题,甚至是多普勒效应。
无线链接也面临着更多挑战。对于有线和光学链路,端点和介质通常固定在适当的位置,因此许多腐蚀影响是相对静止的;对于无线链路,一个或两个端点可能正在移动并且信道本身正在改变,因此接收信号实时地经历许多变化。因此,环路滤波器必须针对动态环境进行设计,超出噪声和衰减等标准问题。
显然,用于高速无线链路的PLL及其滤波器的参数最初是针对最可能的信道条件设置的。对于非常困难的情况的设计有时不使用单个固定滤波器,而是使用具有时间常数的更高级的滤波器和可以“动态”动态调整以匹配条件的其他参数。
-
数据共享与方法共享发布在 极客生涯
全局数据共享 Mobox:原生小程序开发中我们可以通过 mobx-miniprogram 配合 mobx-miniprogram-bindings 实现全局数据共享。二者为外部依赖,我们需要npm或yarn去安装构建相关依赖,才能正常使用。
全局数据共享:共享数据是指多个进程都可以访问的数据,而全局变量是一个进程内的多个单元可共享的数据。
解决组件之间数据共享的问题。开发中常用的全局数据共享方案有:Vuex、Redux、MobX、hooks等。
组件方法共享 behaviors:什么是 behaviors?behaviors 是小程序中,用于实现组件间代码共享的特性,类似于 Vue.js 中的 “mixins”。
behaviors 的工作方式:每个 behavior 可以包含一组属性、数据、生命周期函数和方法。组件引用它时,它的属性、数据和方法会被合并到组件中。每个组件可以引用多个 behavior,behavior 也可以引用其它 behavior。
-
MQ消费失败,自动重试思路发布在 极客生涯
在遇到与第三方系统做对接时,MQ无疑是非常好的解决方案(解耦、异步)。但是如果引入MQ组件,随之要考虑的问题就变多了,如何保证MQ消息能够正常被业务消费。所以引入MQ消费失败情况下,自动重试功能是非常重要的。这里不过细讲MQ有哪些原因会导致失败。
-
MQ重试,网上有方案一般采用的是,本地消息表+定时任务,不清楚的可以自行了解下。
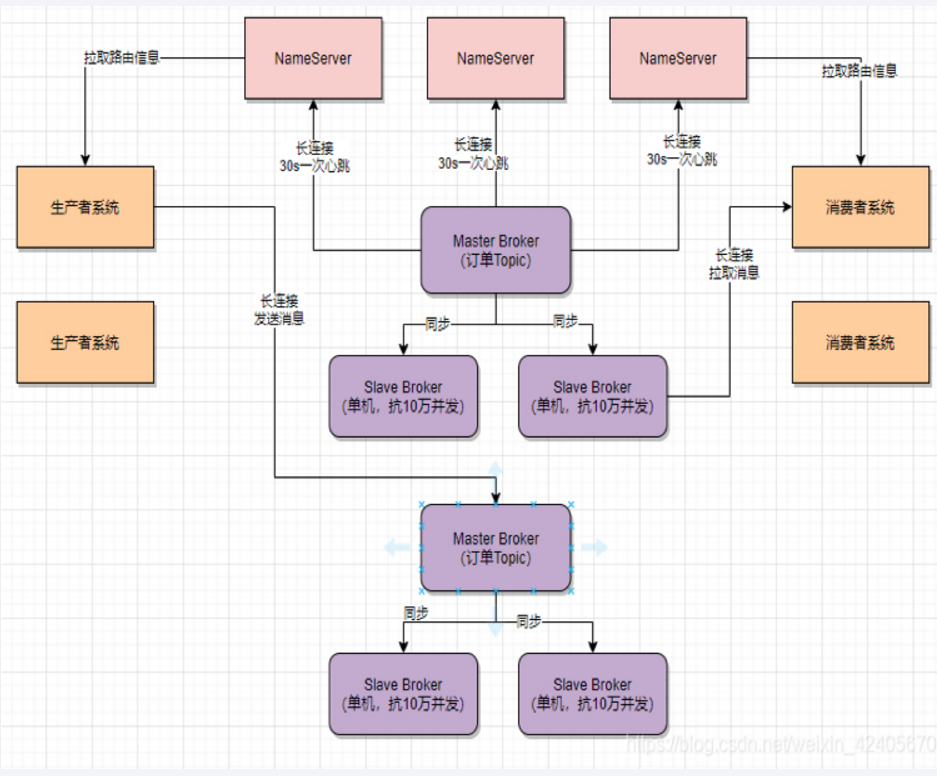
-
MQ(Message Queue)消息队列,是基础数据结构中“先进先出”的一种数据结构。一般用来解决应用解耦,异步消息,流量削峰等问题,实现高性能,高可用,可伸缩和最终一致性架构。
-